跟着例子学express.js
撰写本书的起因,是我的一个故人有学习node后端的兴趣,加之node在我手里落灰已久,于是决定趁着这个机会好好梳理一下,在空闲之余谱一份还算简明的渐进式教程,希望能对各位朋友以及未来又淡忘了express的自己有所帮助.
express-demo,跟着例子学express,先按不同的功能分块学习express.js,从路由,接口,数据库,鉴权等等一块一块地进行独立的基础学习,等有了较为完备的基础,根据一定的架构思想形成一个完整的express.js后端,最后再介绍一些可能用得到的进阶技巧.
源码
仓库有着每一节教程中的完整源码,在阅读本书时,请务必配合源码食用,动手是最好的老师!
进度
当前本书进度100%,历时4个月最终完书(2023/04 - 2023/08)
合作
如本书或者源码有任何的纰漏或者错误,欢迎指正,谢谢!
模块化学习
本章将express分为不同的模块进行独立学习,主要分为以下几方面:
- 处理请求
- 处理响应
- 路由/接口
- 数据库
- 中间件
- 网络安全
- 错误处理
通常来说,建议按从前到后的顺序依次学习,有层层递进的关系。 当有了全面的了解之后,应当就初步具备了写基于 express.js 的完整项目(后端)的能力于水准。
Hello World
本节我们将创建并运行我们的第一个express.js项目,并使用最简单的请求响应
准备工作
- 本书系统环境为 windows10 64Bit
- 请事先在你的开发环境中安装 Node.js,本书使用的是 node v16.17.1
- 推荐使用 VsCode 作为开发工具,有良好的代码提示功能
- 事先安装一个api调试工具,如 postman, apipost等
创建项目
- 创建一个文件夹作为项目根目录
- 下载express依赖
在根目录下执行npm install express - 下载js-text-chart依赖
在根目录下执行npm install js-text-chart,这是一个用于输出字符画的js库,本书在每一个示例中都使用了该库充当starter - 在根目录下新建一个入口文件,如index.js
- 在入口文件中引入依赖
const express = require('express');
const evchart = require('js-text-chart').evchart;
创建服务器
- 先创建一个express实例
const app = express();
- 创建服务器
让我们刚刚创建的app实例挂载到指定的端口,如8080
const server = app.listen(8080);
- 添加服务器运行后的回调函数
是指在服务器成功运行后的一系列操作,常用于输出信息和初始化等,我在这里打印该项目的基本信息
我使用的是内联箭头函数 "()=>{//...}",也可以替换为普通的"function {//...}"
const server = app.listen(8080, () => {
let host = server.address().address;
let port = server.address().port;
let str = "EXPRESS-DEMO";
let mode = [ "close", "far", undefined ];
let chart = evchart.convert(str, mode[0]);
console.log(chart);
console.log("Server is ready on http://%s:%s", host, port);
})
- 跨域策略
默认情况下可能不允许不同域名下进行交互,我们对请求进行一些基本的设置,允许跨域和所有的请求方式请求头格式化,并设置请求头内容为json格式
app.all("*", function (req, res, next) {
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "Content-Type");
res.header("Access-Control-Allow-Methods", "*");
res.header("Content-Type", "application/json;charset=utf-8");
next();
});
第一个接口
概念
前后端交互是在后端暴露的接口进行的,而不同的接口对于后端端口上不同的url路径。前端使用不同的方式(GET,POST...)请求指定的路径,当后端有定义监听某种方式下的某种路径接口时,获取请求携带的数据,对请求进行处理,并返回结果给前端
实践
接下来,我们将添加一个以服务器的根路径(GET)作为返回欢迎信息的接口
app.get('/', function (req, res) {
res.send('Hello World!');
});
以上代码,app实例监听 localhost:8080/ 路径的GET请求,传入2个参数,第一个是请求,第二个是响应
当接收到以GET方式访问该接口的请求时,通过在回调函数中执行res.send返回 Hello World!
测试接口
使用接口测试工具,以GET的形式访问localhost:8080/试试吧!你将会得到一句 Hello World!
第二个接口
第一个接口,我们只是单纯的访问了接口,没有传输任何数据,接下来我们将创建一个以传统的路径请求参数(如: url?id=1)携带数据的接口
实践
定义一个GET形式,路径为 /get 的接口,传入2个参数请求和响应,我们在回调函数中通过req.query来获取路径上的所有请求参数,并将这些参数作为接口的返回值
app.get('/get', function (req, res) {
let requestParams = req.query;
res.send(requestParams);
});
测试接口
使用接口测试工具,以GET的形式访问 localhost:8080/get?id=1&name=evanp 试试吧!你将会得到这两个参数!
下一节-请求类型
请求类型
本节将介绍常见的http请求方式,并站在后端的角度初步感受它们的不同点
各类Http请求
- GET
意图是获取,不会对服务器上的数据产生影响,将要携带的数据放在URL上,通常不带请求体,带了也不一定兼容 - POST
意图是提交,通常用于修改和新增服务器上的数据,偏向新增,路径定位较模糊,要携带的数据通常放在请求体内 - PUT
类似POST,偏向更新,路径定位更明确,要携带的数据通常放在请求体内
★ 幂等性:连续PUT请求后,效果应当只有一次,而POST则会创建多个新资源,不过在REST风格下以及在后台有严格的检验情况下其实这些区别可以忽略
★ 缓存机制:由于PUT的幂等性,不存在缓存,而POST是缓存的,比如你在表单里用POST,不设置提交后清除,刷新页面它会将之前的数据再提交一遍 - DELETE
意图是删除,从服务器上删除某些数据 - HEAD
类似GET,但争对它的响应没有body,只有响应头,常用于判断资源是否存在、链接有效性等 - OPTIONS
意图是询问当前URL允许的请求方法等,常用于跨域请求前的预检和获取服务器的安全控制信息等 - TRACE
路径追踪,回显请求,常用于测试阶段 - PATCH
PUT的超类,指定资源的局部更新 - COPY
请求将页面拷贝到另一个URL,常用于Web资源的备份 - MOVE
请求将页面移动到另一个URL,常用于Web资源的搬迁 - LINK
请求与服务器建立链接 - UNLINK
断开与服务器的链接
其中 GET, POST 最为广泛使用,同时可以使用PUT和DELETE让我们的接口的目的更具有指向性
本书绝大部分接口都将采用类REST风格,即普遍的返回码200,数据格式为json
express处理不同的请求
通过调用get,post,pu,delete...对应不同方法下的路由
由于实际受不同的开发规范和业务环境影响,在这里只以GET和POST举例
get请求
//省略了express项目的创建
class Item {
constructor(name, value) {
this.name = name;
this.value = value;
}
}
//get接口
app.get('/request', function (req, res) {
let result = [];
result.push(new Item("baseUrl",req.baseUrl));
result.push(new Item("fresh",req.fresh)); //请求是否存活
result.push(new Item("hostname",req.hostname)); //请求源域名
result.push(new Item("ip",req.ip)); //请求源IP
result.push(new Item("originalUrl",req.originalUrl));
result.push(new Item("params",req.path)); //路径参数: /x/y/z/
result.push(new Item("protocol",req.protocol)); //请求协议
result.push(new Item("query",req.query)); //查询参数
result.push(new Item("route",req.route)); //请求路由
result.push(new Item("is:Content-Type",req.is('application/json')));
res.send(result);
});
以上代码,定义了GET接口,并返回了关于请求的大部分信息
测试接口
使用api调试工具,尝试用不同的携带数据方法以get形式访问该接口,比较不同的返回结果
post请求
监听相同路径的post请求,开启json解析,一会我们调试时请求体采用最常用的json格式
//启用json解析
app.use(express.json({type: 'application/json'}));
app.post('/post', function (req, res) {
let result = [];
result.push(new Item("baseUrl",req.baseUrl));
result.push(new Item("fresh",req.fresh));
result.push(new Item("hostname",req.hostname));
result.push(new Item("ip",req.ip));
result.push(new Item("originalUrl",req.originalUrl));
result.push(new Item("params",req.path));
result.push(new Item("protocol",req.protocol));
result.push(new Item("query",req.query));
result.push(new Item("body",req.body));
result.push(new Item("route",req.route));
result.push(new Item("is:Content-Type",req.is('application/json')));
res.send(result);
});
测试接口
使用api调试工具,尝试用不同的携带数据方法以post形式访问该接口,比较不同的返回结果
不限方法
如果你想让某个路由能以任意方法访问:
app.use('/any', function (req, res) {
res.send('Bad World!');
});
尝试使用各种方法去访问 127.0.0.1:8080/any,都可以得到Bad World!
下一节-处理请求数据
处理请求数据
本节将具体介绍express后端处理请求源携带数据的一些方法和技巧
动态路径
很多时候我们需要处理一些类似但有操作差别或不同对象的业务,我们可以监听一段基本路径,将其中某一个段或者某几段路径作为变量,在接口中根据不同的路径变量执行不同的业务操作,这是一种REST风格比较鲜明的动态接口设计策略
实践
由于post也可以url传参,本节所有实例均采用post请求
第一个接口
这个接口以 /request/data/ 作为基路由,之后的kind变化的,在接口内部根据kind的值进行分支化处理。我指定了kind的3个值:PathVarible, RequestParam 和 body.
所有的路径参数则可以由req.params(大概是个json对象)来获取,我要指定获取kind的值,就req.params.kind,而静态路径变量的值就等于它名字.
//忽略了express项目的创建和基本配置
class Item {
constructor(name, value) {
this.name = name;
this.value = value;
}
}
//启用json解析请求体
app.use(express.json({type: 'application/json'}));
app.post('/request/data/:kind', function (req, res) {
let result = [];
if (req.params.kind == 'PathVarible') {
result.push(new Item("lesson","路径变量"));
result.push(new Item("info","在express中叫做params,路径上每个被双单斜杠'/'隔开的一个个词语就是路径参数,当你需要在同一个接口内动态响应不同的情景时,可以让某一处或多出的路径参数前面加上一个冒号,长得比较像vue中的动态绑定,动态路径在REST风格上被广泛运行,比如操作某个用户: 'user/:id => 'user/1"))
} else if (req.params.kind == 'RequestParam') {
result.push(new Item("lesson","请求参数"));
result.push(new Item("info","在express中叫做query,和路径变量相比,前者更像是前端主动携带参数去访问特定的资源,而后者更像是后端要求必须携带的数据,前端被迫携带,反应在路径上形式一般是: '/stu?class=2&sid=1&name='evanp',在基本路径之后添上一个问号,然后在后面加上请求的参数,不同参数之间用'&'符号隔开"))
} else if (req.params.kind == 'body') {
result.push(new Item("lesson","请求体"));
result.push(new Item("info","路径变量和请求参数的数据都是透明的,这非常不注重隐私,因此更多时候前端应该将携带的数据放在请求体内进行传输。请求体的形式有很多,最常用的是表单和JSON,请在路径后新增一个路径变量,form-urlencode, multi-form-data或json导向不同的接口进行查看"));
} else {
result.push(new Item("error","这个参数不认识"));
}
res.send(result);
});
接口测试
请使用接口调试工具,带上路径查询参数(query),然后修改不同的kind为不同的值,去POST访问 localhost:8080/request/data/kind,看看它们的返回结果,注意kind前不要加冒号了,冒号是用来让express知道这段路径是可变的
第二个接口
当第一个接口的某一个分支还可以有后续的操作时,可以再开一个接口以它作为基路由,往后新增动态路径,比如我现在要让body可以再导向不同的分支,就再开一个 /request/data/body/:kind 接口
app.post('/request/data/body/:kind', function (req, res) {
let result = [];
if (req.params.kind == 'json') {
result.push(new Item("lesson","json请求体"));
result.push(new Item("body",req.body));
result.push(new Item("info","express想解析json形式的body,必须先开启express.json: 'app.use(express.json)',之后就可以用req.body来接收请求体了"));
result.push(new Item("trick","进阶技巧,读取请求体时可以用match模式匹配成自己想要的格式或命名,常用于实体注入及转化等"));
} else if (req.params.kind == 'form-urlencode') {
result.push(new Item("lesson","form-urlencode请求体"));
result.push(new Item("body",req.body));
} else if (req.params.kind == 'multi-form-data') {
result.push(new Item("lesson","multi-form-data请求体"));
result.push(new Item("body",req.body));
} else {
result.push(new Item("error","这个参数不认识"));
}
res.send(result);
});
接口测试
请使用接口调试工具,带上JSON请求体,去POST访问 localhost:8080/request/data/body/kind,修改不同的kind,看看它们的返回结果
获取路径参数
基础
路径参数是指 '/url?id=1&name=evanp' 这种url中的id和name,是明文的不具有隐私性
可以通过 req.query获取
app.post('/request/data/query/info',checkQuery, (req, res)=> {
res.send(req.query);
});
尝试用接口调试工具访问 localhost:8080/request/data/query/info,并携带上任意的query参数
Query预检
在实际场景中,每个接口会指定需要哪些名字的query参数,假设上面的接口需要id和name,则需要保证前端确实给接口传递了这两个query参数,express没有像springboot那样在入参的时候就可以规定检验,我们必须亲自对传过来的query进行检验。而这部分检验的操作不建议包含在我们接口的主体回调函数内,而应作为一个中间件,在回调之前就完成检验:
定义一个检查query的函数,判断是否有id和name,是的话继续,不是的话直接返回错误信息
function checkQuery(req,res,next) {
if (req.query.id == undefined ||
req.query.id == null ||
req.query.name == undefined ||
req.query.name == null){
res.send({"msg": "query不齐全"});
} else {
next();
}
}
在接口入参时引入该中间件函数
app.post('/request/data/query/info',checkQuery, (req, res)=> {
res.send(req.query);
});
尝试用接口调试工具访问 localhost:8080/request/data/query/info,并比较不携带id,name和携带了id,name的返回结果
获取请求体
JSON请求体
引入以下代码一次即可
app.use(express.json({type: 'application/json'}));
表单(x-www-form-urlencoded)
x-www-form-urlencode将表单数据编码为URL形式的字符串
引入以下代码一次即可
app.use(express.urlencoded({extended: true}));
关于extended参数,是指将(URL编码字符串形式的)表单数据解析为简单对象还是深度嵌套对象.
什么意思呢?就比如当extended=false时,表单里是这么传数据的:
其中,有两个相同的键名: 比如传了2个x
解析后该字段的指将是所有它们的值的数组集合:x=1&x=2 -> {'x': ['1','2']},即便2个x都为1,也是数组: {'x': ['1','1']}
其中,又有的键名是以对象属性格式传递的,比如下图的user[uname]:
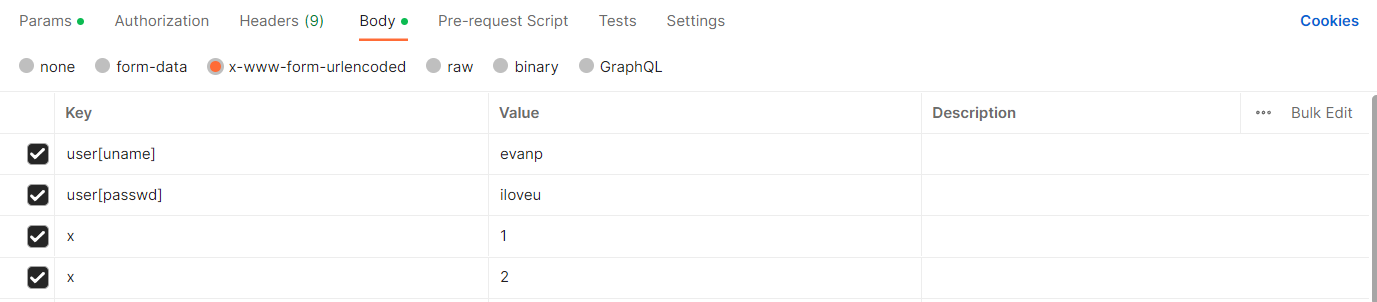 假如我们在api调试工具访问之前那个body/form-urlencode接口,同时以表单方式传输了这两种情况的数据,将得到这样的返回结果:
假如我们在api调试工具访问之前那个body/form-urlencode接口,同时以表单方式传输了这两种情况的数据,将得到这样的返回结果:
[
{
"name": "lesson",
"value": "form-urlencode请求体"
},
{
"name": "body",
"value": {
"user[uname]": "evanp",
"user[passwd]": "iloveu",
"x": [
"1",
"2"
]
}
}
]
当extended=true时,则是:
[
{
"name": "lesson",
"value": "form-urlencode请求体"
},
{
"name": "body",
"value": {
"user": {
"uname": "evanp",
"passwd": "iloveu"
},
"x": [
"1",
"2"
]
}
}
]
通过对比我们可以发现,extended=false时express比较憨,不会智能解析user到一个对象上去;智能解析的用处,我想大概是省的我们手动一条条注入属性到对象上去了
表单验证
对于请求参数我们有验证的需求,同样的,表单验证自然也会有,甚至可能需求性更高,因为需要考虑到安全问题
如果没有什么特殊要求,可以自己写一个中间件函数来检查表单,如果有比较高级的需求,可以借助线程的js库,如express-validator等
表单(multi-form-data)
这个是可以一边传字符串,还可以传文件的表单,其实就是基础表单的一个升级版
需要事先安装multer依赖: npm install multer
引入依赖中间件:
const multer = require('multer');
const uploads = multer();
在需要接收文件的接口引入该中间件uploads:
app.post('/request/data/body/:kind', uploads.any(), function (req, res)
在主体回调函数中通过req.files可以获取到所有的文件:
console.log(req.files); //写在multi-form-data分支下,方便区分
测试接口
使用api调试工具的复合表单携带文件发送请求到 body/multi-form-data 接口,查看我们的控制台:
[
{
fieldname: 'file',
originalname: 'C.jpeg',
encoding: '7bit',
mimetype: 'image/jpeg',
buffer: <Buffer ff d8 ff e0 00 10 4a 46 49 46 00 01 01 01 00 48 00 48 00 00 ff db 00 43 00 0a 07 08 09 08 06 0a 09 08 09 0c 0b 0a 0c 0f 1a 11 0f 0e 0e 0f 1f 16 18 13 ... 9752 more bytes>,
size: 9802
}
]
是的,我刚刚传了一张名为 C.jpeg 的图片到服务器
下一节-响应
响应
上一节讲完了请求,这一节我们就来讲一下响应吧!
本节作为初级内容,将罗列比较常用的响应方法以及其简单的使用形态
准备工作
拷贝第一节Hello World项目
status
res.statue(status code),这是很实用的一个方法,设置响应体的Http状态码,虽然REST-Apid的风格的是统一200,但在express.js中,有些情景下你必须设置status code为某个值
res.status(404);
send
res.send(content),将任意类型的内容放在响应体内返回给请求源
app.get('/', function (req, res) {
res.send('Hello World!');
});
也可以接在status后面:
res.status(200).send(<p>hello world</p>);
end
res.end(),用于快速结束不需要返回数据的场景下的响应,不过end()也可以传送数据,但性能消耗较大,不建议用res.end传数据和信息
//END
app.get('/end',(req,res)=>{
res.status(404).end();
})
json
res.json(content),以json格式的请求体返回给请求源,可能会收到跨域保护的限制,因此往往需要我们顶上设置的一串Allow
//json - 同源限制
app.get('/json',(req,res)=>{
let resp = {
code: 200,
msg: "json",
toPrint: function(){
console.log(`resp[code: ${this.code}, msg: ${this.msg}]`);
}
}
res.jsonp(resp);
})
jsonp
res.jsonp(content),jsonp是开发者们自研的一种不正统的数据格式,和json基本一样,但不太会被跨域保护给拦着
//jsonp - 更容易的解决跨域
app.get('/jsonp',(req,res)=>{
let resp = {
code: 200,
msg: "jsonp",
toPrint: function(){
console.log(`resp[code: ${this.code}, msg: ${this.msg}]`);
}
}
res.jsonp(resp);
})
sendFile
res.sendFile(path,options),静态传输文件,不能直接使用相对路径
//sendfile,传输文件
app.get('/sendfile',(req,res)=>{
//只能是静态路径,需要相对路径的话有很多方法,以下是其中一个
res.sendFile("hello.txt", {root: __dirname});
})
download
res.download(path),下载传输文件,这个可以直接使用相对路径
//download,下载文件
app.get('/download',(req,res)=>{
//可以直接相对路径
res.download("./hello.txt");
})
sendStatus
res.sendStatus(status code),设置响应码,并返回信息为该状态码预设好的文本,比如res.sendStatus(404),则响应的状态码是s404,返回的信息是'not Found'
//sendstatus
app.get('/sendstatus',(req,res)=>{
//预先写好的httpStatus组合,改一下试试,如果你输入的status码不存在,msg将变成这个码的数字
res.sendStatus(404);
})
location
res.location(route),REST接口之间的转发,必须设置status为300~309之间的数字,才能成功转发
//location
app.get('/location/1',(req,res)=>{
//转发到最早的helloworld路由去
res.location('/').status(302).send();
})
//location/2
app.get('/location/2',(req,res)=>{
//转达到下面定义的这个接口
res.location('/location/index').status(302).send();
})
app.get('/location/index',(req,res)=>{
res.send("welcome to learn express.js by demos");
})
redirect
res.redirect(),路由重定向,这个比较特殊,我们放到路由控制那一节再讲
下一节-Sql-knex增删改查
Sql增删改查
本节使用knex作为sql框架,以sqlite数据库为例
准备工作
knex是一个运行在各自数据库Driver上的框架,因此需要安装相应的js版数据库Driver,如: PostgreSQL -> pg, mysql/mariadb -> mysql, sqlite -> sqlite3...
- 安装sqlite3依赖
npm install sqlite3 - 安装knex依赖
npm install knex - 引入依赖
const app = express();
const knex = require('knex');
- 建议安装一款合适的数据库界面工具,笔者使用的是Beekeeper Studio.
创建项目
拷贝第一节HelloWorld的项目
创建sqlite连接
指明client为sqlite3(刚刚安装的sqlite3依赖),并指明要操作的sqlite数据库路径
const sqlite = knex({
client: 'sqlite3',
connection: {
filename: './data.db',
},
});
创建了一个连接实例后,会自动创建一个连接池,因此初始化数据库只会发生一次
连接配置
sqlite3默认的是单连接,如果你希望连接池有更多的连接,创建时带上pool:
const sqlite = knex({
client: 'sqlite3',
connection: {
filename: './data.db',
},
pool: { min: 0, max: 7 }
});
创建连接池的回调
用于检查连接池是否正常,通常不需要这步
pool: {
afterCreate: function (conn, done) {//...}
}
acquireConnectionTimeout
连接超时时间
日志
knex内置了打印警告、错误、弃用和调试信息的日志函数,如果你希望自定义日志操作,可以在log项里重写它们
log: {
warn(message) {
},
error(message) {
},
deprecate(message) {
},
debug(message) {
}
}
数据表
建表
语法: sqlite.schema.createTable(表名, table=>{表结构})
添加一个PUT接口,监听 127.0.0.1:8080/db/:tbname
根据我们想创建的表名尝试创建一个表,注意: sql执行是异步的,为了得到结果,建议使用 async/await 语法糖(当然你就是喜欢地狱回调也不是不行)
app.put('/db/:tbname', async function (req, res) {
let resultSet = null;
try {
// Create a table
resultSet = await sqlite.schema
.createTable(req.params.tbname, table => {
table.increments('id');
table.string('uname');
table.string('passwd');
})
// Finally, add a catch statement
} catch(e) {
console.error(e);
resultSet = e;
};
res.json(resultSet);
});
瞅瞅控制台:
sqlite does not support inserting default values. Set the `useNullAsDefault` flag to hide this warning. (see docs https://knexjs.org/guide/query-builder.html#insert).
嗯?sqlite不支持default?不用管他,去看数据库,反正成功创建了user表,你要是加了useNullAsDefault这个flag,反而会告诉你 not supported by node-sqlite3
const sqlite = knex({
client: 'sqlite3',
connection: {
filename: './data.db',
},
});
删表
语法: sqlite.schema.deleteTable(表名)
app.delete('/db/:tbname', async function (req, res) {
try {
// Delete a table
await sqlite.schema.dropTable(req.params.tbname);
// Finally, add a catch statement
} catch(e) {
console.error(e);
};
res.json(null);
});
表记录crud
增
往user表里面插入一条新的记录
app.use(express.json({type: 'application/json'}));
app.put('/db/:tbname/record', async function (req, res) {
/*前端请求体格式:
{
"uname": "evanp",
"passwd": "iloveu"
}
*/
let resultSet = null;
try {
// Insert a record
resultSet = await sqlite(req.params.tbname).insert(req.body);
// Finally, add a catch statement
} catch(e) {
console.error(e);
resultSet = e;
};
res.json(resultSet);
});
尝试用api调试工具PUT 127.0.0.1:8080/db/user/record,携带相应的请求体,将会得到[1],这是影响的记录数,1代表成功了
查
从user表里查询uname=我们刚刚插入的记录
app.get('/db/:tbname/record', async function (req, res) {
//前端携带query: uname=evanp
let resultSet = null;
try {
// select a record where uname=xxx
resultSet = await sqlite(req.params.tbname).select('*').where('uname',req.query.uname);
// Finally, add a catch statement
} catch(e) {
console.error(e);
resultSet = e;
};
res.json(resultSet);
});
尝试用api调试工具GET 127.0.0.1:8080/db/user/record?uname=evanp,将会得到:
[
{
"id": 1,
"uname": "evanp",
"passwd": "iloveu"
}
]
改
接下来我们修改uname=evanp这条记录的passwd为123456
app.post('/db/:tbname/record', async function (req, res) {
//前端携带query: uname=evanp
/*前端请求体格式:
{
"passwd": "123456"
}
*/
let resultSet = null;
try {
// select a record where uname=xxx
resultSet = await sqlite(req.params.tbname).update(req.body).where('uname',req.query.uname);
// Finally, add a catch statement
} catch(e) {
console.error(e);
resultSet = e;
};
res.json(resultSet);
});
尝试用api调试工具POST 127.0.0.1:8080/db/user/record?uname=evanp,并携带相应请求体,将会得到: [1],这代表影响记录1条,成功了
删
接下来我们删除uname=evanp且passwd=123456的这条记录
app.delete('/db/:tbname/record', async function (req, res) {
/*前端请求体格式:
{
"uname": "evanp",
"passwd": "123456"
}
*/
let resultSet = null;
try {
// select a record where uname=xxx
resultSet = await sqlite(req.params.tbname).del().where(req.body);
// Finally, add a catch statement
} catch(e) {
console.error(e);
resultSet = e;
};
res.json(resultSet);
});
尝试用api调试工具DELETE 127.0.0.1:8080/db/user/record,并携带相应请求体,将会得到: [1],这代表影响记录1条,成功了
原生sql
当然了,如果你需要直接使用sql语句,也是可以的,调用raw(sqlStr)即可,既可以作为某一段sql的绑定,也可以直接当作整句sql
格式: knex.raw(sql, [bindings]
sqlite.raw("select * from user",[1]).then((resp)=>{//..})
在这里不做介绍
总结
以上给出了使用knex实现增删改查的基本操作,这些方法并不是唯一的,在实际开发中往往要应对更复杂的场景,基础crud也是远远不够的
关于knex的更多拓展使用方法,请移步knex官方文档https://knexjs.org/guide/
下一节-Sql-ORM增删改查
Sql-ORM增删改查
ORM框架: 对象关系映射,面对对象sql
本节使用sequelize作为orm-sql框架,数据库为sqlite
准备工作
同样的,需要安装相应的js版数据库Driver,如: PostgreSQL -> pg, mysql/mariadb -> mysql, sqlite -> sqlite3...
- 安装sqlite3依赖
npm install sqlite3 - 安装sequelize依赖
npm install sequelize - 引入依赖
const app = express();
const { Sequelize } = require('sequelize');
- 建议安装一款合适的数据库界面工具,笔者使用的是Beekeeper Studio.
创建项目
拷贝第一节HelloWorld的项目
创建sqlite连接
指定方言为sqlite,持久化路径为本目录下的data.db
const sqlite = new Sequelize({
dialect: 'sqlite',
storage: './data.db'
})
定义表模型
sequelize主打一个面对对象sql,因此我们要建立一个对应数据表的类
就和上一节一样,弄一张一模一样的user表吧:
- 引入DataTypes
const { Sequelize,DataTypes } = require('sequelize');
- 定义User对象
Model.init(schema,options)
const User = sqlite.define('User', {
id: {
primaryKey: true,
type: DataTypes.INTEGER,
allowNull: false,
autoIncrement: true
},
// 在这里定义模型属性
uname: {
type: DataTypes.STRING,
allowNull: true
},
passwd: {
type: DataTypes.STRING
// allowNull 默认为 true
}
}, {
// 直接指定表名,不指定的话sequelize将默认以模型的复数形式作为表名
tableName: 'user'
});
还有另一种方法,效果是一样的,看个人喜好使用:
- 额外引入Model
const { Sequelize,DataTypes,Model } = require('sequelize');
- 初始化User类
Model.init(schema,options)
User继承Model类
class User extends Model {};
User.init(
{
id: {
primaryKey: true,
type: DataTypes.INTEGER,
allowNull: false,
autoIncrement: true
},
// 在这里定义模型属性
uname: {
type: DataTypes.STRING,
allowNull: true,
},
passwd: {
type: DataTypes.STRING,
defaultValue: '123456', //默认值
//allowNull 默认为 true
}
},
{
// 这是其他模型参数
sqlite, // 我们需要传递连接实例
modelName: 'User1', // 我们需要选择模型名称,
// 直接指定表名
tableName: 'user',
}
);
模型同步
Model.sync: 底层执行的是 create table if not exist
- 如果数据库中不存在对应的表,将根据模型直接创建表;若存在,不操作
Model.sync({force: true}): 底层是先 drop if 然后 create - 如果表已存在,将删除再根据模型创建表
Model.sync({alter: true}): - 如果表已存在,将修改表结构使之与模型匹配
花里胡哨的,总之就是保证数据库中有和该模型对应的表
创建user表
我们使用User.sync()创建一张user表
app.put('/db/user', async function (req, res) {
let what = await User.sync();
res.json(what);
});
使用api调试工具PUT 127.0.0.1:8080/db/user,将会得到1,注意只要能成功映射到到数据表都是1
用Beekeeper查看我们的user表,你会发现和我们定义的模型有点不一样:多了2个字段——createdAt和updatedAt,即创建时间和修改时间
sequelize会自动管理这两个字段,注意当你使用了其他的sql工具修改表,这两个字段不会自动更新
如果你不想要这两个值,或者想换个名字,可以在定义模型时往options添加这些设置:
// 禁止createdAt和updatedAt
timestamps: false,
// 只禁止createdAt
createdAt: false,
// 给updatedAt换个名字
updatedAt: 'updateTime'
删除user表
drop()方法,底层是 drop if,既可以作用于模型,也可作用于数据库:
sqlite.drop(); //这将删除当前data.db下所有的表
我们使用User.drop()来删除user表
app.delete('/db/user', async function (req, res) {
let what = await User.drop();
res.json(what);
});
使用api调试工具PUT 127.0.0.1:8080/db/user,将会得到1,注意即使表已经没了,也是1
数据表crud
增
在操作表记录前,我们先通过模型(Model.build)创建一个实例,然后调用save()将这个实例插入到表中
当然,如果你从前端拿来的数据不需要进行处理和转化就能拿来用,也可以直接用Model.create插入记录
app.use(express.json({type: 'application/json'}));
app.put('/db/user/record', async function (req, res) {
/**前端请求体
{
"uname": "evanp",
"passwd": "iloveu"
}
*/
try {
let user = User.build(req.body);
let what = await user.save();
// let what = await User.create(req.body);
res.json(what);
}catch(e){
res.json(e);
}
});
使用api调试工具PUT 127.0.0.1:8080/db/user/record,携带相应的请求体,将会得到:
{
"id": 1,
"uname": "evanp",
"passwd": "iloveu",
"updatedAt": "2023-03-19T08:03:37.964Z",
"createdAt": "2023-03-19T08:03:37.964Z"
}
是的,添加记录成功后它会顺便把整条记录查出来作为返回结果
Ok,那么现在user表里已经有了id=1的一条记录了,让我们试一下创建相同id的记录会怎么样...
服务器直接挂了,我们可不希望这样,这意味着有任何不妥的sql都可能导致服务器崩溃,那怎么办呢?
有的朋友可能记起来了,在上一节中,使用了try-catch语法糖包裹sql操作,这是一种不错的方法
查
sequelize模型内置了一些方法使得我们可以基于模型直接查询
- findAll 查找全部,底层是
select * from ... - findOne 查找一个,底层是
select * from ... LIMIT 1 - findByPk 根据主键查找
- findAndCountAll 查找并返回符合的总条数,常用于分页
- findOrCreate 找不到就创建
这些方法都可以添加options参数设置WHERE,LIMIT等限制条件
我们使用findOne来查询evanp和用户名和密码都对的上的一条记录:
//我为了方便直接url传参了,实际上为了隐私,至少应该放在请求体内
app.get('/db/user/record', async function (req, res) {
let evanp = await User.findOne({where: req.query});
res.json(evanp);
});
如果你只需要查询其中某些字段,就在options中设置attributes:
User.findAll({
attributes: ['id','uname']
});
如果想给字段取别名,就比如像这样给id取名uid:
User.findAll({
attributes: [['id','uid'],'uname']
});
改
Model.update(修改项,限制)
app.post('/db/user/record', async function (req, res) {
/*请求体
{
"set":{
"passwd": "123456"
},
"where": {
"uname": "evanp",
"passwd": "iloveu"
}
}
*/
let what = await User.update(req.body.set,{where: req.body.where})
res.json(what);
});
使用api工具进行调试,修改成功将返回1,修改失败将返回0(找不到/改不了)
删
Model.destroy(限制)
app.delete('/db/user/record', async function (req, res) {
/*请求体
{
"uname": "evanp",
"passwd": "123456"
}
*/
let what = await User.destroy({where: req.body})
res.json(what);
});
使用api工具进行调试,删除成功将返回1,删除失败将返回0(找不到/删不了)
原生Sql
当然了,如果你需要直接使用sql语句,也是可以的,连接实例.query(sqlStr)即可
通常,返回结果包含2个值,一个是结果数组,一个是相关信息
app.post('/db/user/record/freely', async function (req, res) {
/*json请求体
{
"sql": "xxx"
}
*/
let what = null;
try {
what = await sqlite.query(req.body.sql);
} catch (e) {
what = e;
}
res.json(what);
});
执行insert前要注意,如果这张表是经过sequelize同步的,也许会有那两个时间字段的,别忘了
本节的例子仅仅为了演示在express.js中如何运用sequelize操作数据库,关于sequelize的更多拓展和高级使用方法,请移步sequelize官方文档https://www.sequelize.cn/
下一节-路由控制
路由控制
准备工作
拷贝第一节HelloWorld项目
动态路由
这个最初我们就接触到了,路径中某一段前面加冒号
//路径变量-动态路由
app.get('/:var',(req, res)=>{
res.send(req.params.var);
});
路由匹配
利用通配符 * 匹配符合的所有路由
- 全通配
定义时,以 * 结尾,或者 * 之后除了斜杠没有其他字符,匹配*之后所有的路由
//全部匹配,囊括了match之下的所有路由,即便前端请求路径时在后面再来几段,也会被当作一个字符串 /x/1/6 -> '/x/1/6'
//慎用,必须确保其他独立的路由不会被覆盖了
app.get('/matchall/*',(req, res)=>{
let what = {
params: req.params,
theVar: req.params['0']
}
res.send(what);
});
前端发来请求时,如何有2个定义的接口都能匹配到,优先匹配先定义的
//不起效
app.get('/matchall/w/xf',(req, res)=>{
res.send("there is w.xf");
});
- 局部通配
在两个字符之间(斜杠不算,除非你转义过了)使用 *,匹配这两个字符中间夹任何一段字符串的路由:
xAy,xBy,xvenapy...
//xy中间随便夹
app.get('/match/x*y', function (req, res) {
res.send('xy肉夹馍')
})
//除非通配符后面有除了斜杠以外的字符,不然全部被盖
app.get('/match/w*/x', function (req, res) {
res.send('除非通配符后面有除了斜杠以外的字符,不然全部被盖')
})
- 动态字符(串)
问号前的字符可有可无,gback,goback
//问号前面这个字符可有可无
app.get('/match/go?back',(req, res)=>{
res.send("问号前面这个字符可有可无");
});
问号前被括号括住的字符串可有可无,xback,xgoback
app.get('/match/x(go)?back',(req, res)=>{
res.send("问号前面这个字符串可有可无,注意被括住的字符串前面不能没有字符");
});
加号前的字符可以重复,goback,gooback,goooback...
//可匹配到多个路由时,优先匹配先定义的路由
//一个或多个问号前字符
app.get('/match/go+back',(req, res)=>{
let what = {
match: '/match/go+back',
url: req.url,
tip: "加号前面的那个字符可以无限重复"
}
res.send(what);
});
正则匹配
可用于复杂路由的匹配,在路由中局部正则时,记得用括号包住
//正则匹配
//匹配了127.0.0.1:8080/x//数字useremm//
app.get('/x/(\/[0-9]useremm\/)', function (req,res) {
console.log(req.body);
res.send("正则可用于复杂路径的匹配");
})
路由重定向
有时候我们希望某些情况下将路径转发到其他路径,比如404页面之类的
格式: res.redirect(status, url)
status是干什么的?对于重定向后的路由不同的请求方法应该使用不同的status:
- GET
//转发到 GET /1/2/3/4/5
app.post('/redirect',(req,res)=>{
res.redirect(301,'/1/2/3/4/5');
});
app.get('/1/2/3/4/5',(req,res)=>{
res.send("上山打老虎");
})
301或302都是可以的,301代表临时,302代表永久
接下来我们把转发后的路由改成POST,再去访问redirect:
app.post('/1/2/3/4/5',(req,res)=>{
res.send("上山打老虎");
})
是的,响应不到了,转发到POST路由,应当使用307或308,前者临时后者永久
res.redirect(301,'/1/2/3/4/5');
- JSON与重定向
开启app.use(express.json),再尝试访问redirect,结果又得不到响应了,这是为什么?
开启了json解析后,请求变成了json,请求已经不是原始的请求了,变成了json对象,是没办法被转发的
因此在有需要重定向的时候,我们不应该全局json解析了,而是在需要json解析的路由上开启json解析:
建个需要使用json解析的测试接口:
app.put('/some/json',(req,res)=>{
res.send(req.body);
});
自定义一个选择性body-json的中间件,判定 PUT:/some/json 时局部开启json解析:
app.use((req, res, next) => {
// 判断当前请求路径是否需要解析JSON请求体
if (req.path === '/some/json'&& req.method.match("PUT")) {
bodyParser.json()(req, res, next);
} else {
next();
}
});
尝试用api调试工具访问redirect,重定向成功了,再访问/some/json,也能成功打印请求体.
下一节-JWT基础鉴权
JWT基础鉴权
Web安全是Web应用中非常重要的一环,主要由后端和服务器承担安全保障
面对请求源,后端有着各种各样的鉴权机制: session,cookie,token,jwt,OAuth,OAuth2,api-key,signature...
本节以jwt为例,演示一个极简的token鉴权
准备工作
- 拷贝第一节HelloWorld项目
- 安装一种jwt依赖(本节使用jsonwebtoken)
实践
接下来我们使用jsonwebtoken来实现最常见的登录鉴权,登录成功后返回一个token,之后凭借这个token去访问另外的路由
- 首先引入jwt依赖
const jwt = require('jsonwebtoken');
- 定义一个密钥
之后我们会利用这个密钥生成token,和检验token
const secret = 'mysecretkey';
- 写个登录时生成token的函数
传入用户名和密码,检验密码,正确就生成一个token
生成token: jwt.sign(标志,密钥,选项(生命周期等))
function getToken(user) {
let token = null;
const payload = {
uname: user.uname,
};
if (user.uname == 'root' && user.passwd == 'root') {
token = jwt.sign(payload, secret, { expiresIn: '1h' });
}
return token;
}
- 写一个访问时检验token的函数
传入req,res,next,从请求头中取出名字为'token'的一个token,若请求头里不带token则返回请求报告没token,token校验通过了则放行
function checkToken(req, res, next) {
const token = req.headers['token'];
if (!token) return res.status(401).json({ message: 'No token provided.' });
jwt.verify(token, secret, (err, decoded) => {
if (err) return res.status(500).json({ message: 'Failed to authenticate token.' });
req.userId = decoded.id;
next();
});
}
- 编写登录接口
app.post('/login', (req, res) => {
let user = req.body;
let token = getToken(user);
if(token!=null) {
res.send(token);
} else {
res.status(401).send("wrong");
}
});
- 编写一个需要校验token的接口
将token检验函数作为中间件挂载到 /root 路由上
app.get('/root', checkToken, (req, res) => {
res.send('hello root user!');
});
接口测试
尝试用api调试工具先访问 login 接口,利用正确的用户名和密码获取token,然后用得到的token去访问 root 接口
下一节-全局错误处理
全局错误处理
在前面几节里,我们处理异常的方法都是手动在可能引发异常的地方捕捉错误,这固然是必要的,可以有针对性得处理异常,但很多时候,有许多潜在的异常,有一句话叫永远不要相信输入的数据,你永远都不知道什么时候可能会以什么方式触发某些阴间异常从而造成系统崩溃。因此,我们需要有一位好帮手能帮助我们捕获各种错误
而这位好帮手就是,异常处理中间件
自定义异常处理中间件
同步异常
异常处理中间件需要传入4个参数: err,req,res和next,这样才会被express识别为异常处理中间件
创建一个exhandler,并挂载到服务器上:
注意: 挂载异常处理中间件的行为必须位于所有定义的接口之下,至于理由,会在下一节《中间件》中给出解答
let exhandler = (err, req, res, next)=> {
console.error('Error:', err.message);
res.status(500).json(err);
}
app.use(exhandler);
我们在helloWorld接口中人为抛出一个异常试一下,可以直接throw,也可以传递给next(事实上,意外的异常发生时,会被express捕获并传递给next,然后再丢给我们的异常处理中间件)
app.get('/', (req, res, next)=> {
const err = new Error();
err.name = '无法访问';
err.message = '对不起,网站正在维护中';
// next(err);
throw err;
});
测试
使用api调试工具GET 127.0.0.1:8080/,我们的程序不会崩溃,并且你将得到被封装好的错误信息,并且响应码是500。
{
"name": "无法访问",
"message": "对不起,网站正在维护中"
}
异步异常
上面的异常是产生在串行的代码中的,那如果在异步操作中产生了异常呢?
我们弄一个异步异常的接口试一下:
app.post('/', async (req, res, next)=> {
res.send(await error()).end();
});
function error() {
let err = new Error('网站维护');
err.message = "自定义的错误";
return Promise.reject(err);
}
POST 127.0.0.1:8080/,程序报错,之前的中间件并未捕获到这个错误。
可以手动在处理函数内加上 try-catch 语句块,但这样比较繁琐,一个更方便的方法是使用 express-async-errors:
npm i express-async-errors
然后引入即可:
require('express-async-errors');
POST 127.0.0.1:8080/,这次成功捕获到了异步错误!
下一节-中间件
中间件
中间件,估计大家在前几节里面听的耳朵都要出茧子了吧!一直提到,一直不讲。别急,这不来了嘛
准备工作
拷贝第一节Hello World项目
什么是中间件
如果正在阅读本书之前的你,已经有过一些其他框架或语言的后端开发经历,那理应是知道中间件这个东西的。当然也不绝对,比如隔壁某个框架太贴心了,以至于笔者都觉得理所应当,在撰写本节时,才惊觉原来在那个框架里竟内置了这么多的中间件。
由于 express.js 是一个轻量级后端框架,因此中间件的身份变得非常的突出。
在 express.js 中,中间件(Middleware)是指应用中,用于额外处理 HTTP 请求和响应的函数,通常不涉及主体业务。中间件函数可以访问请求对象(request object)(req)、响应对象(response object)(res)和应用程序中处理请求-响应循环流程的下一个中间件函数(next)。 在 express.js 应用中,可以使用 use() 方法来挂载中间件函数。在处理 HTTP 请求时,express.js 会按照添加中间件函数的顺序依次调用它们,直到响应被发送为止。如果在某个中间件函数中没有调用 next() 方法,则请求-响应循环流程会在该中间件函数队伍中提前终止。
中间件的应用主要在日志,鉴权,预检,初步数据处理,异常处理等等。接下来,举几个简单的例子:
路由中间件
是的,路由可以单独抽离出来的中间件,可以挂载在app也可以作为子路由挂载在其他路由上
//Route coule be middleware
const routers = express.Router();
routers.get('/', function (req, res) {
res.send('Hello World!');
});
routers.post('/', (req,res)=> {
res.send('Bad World!');
})
app.use(routers)
鉴权中间件
鉴权中间件,可以被挂载到单个路由,一系列路由以及app全局
这是一个检查请求头token的鉴权中间件:
//鉴权中间件,可以被挂载到单个路由,一系列路由以及全局
let auth = (req,res,next) => {
if (req.headers['token']!='evanp'){
return res.send('Unauthorized');
}
next()
}
const router_root = express.Router();
router_root.post('/root', auth, (req,res)=> {
res.send('Hello root!')
})
app.use(router_root);
异常处理中间件
异常处理中间件,全局捕捉异常,防止服务器崩溃
//异常中间件
const exhandler = (err,req,res,next)=> {
return res.json({ "err":{ "name": err.name, "msg": err.message }});
}
app.use(exhandler);
//测试接口
router_err.get('/error', auth, (req,res)=> {
const err = new Error("error!");
err.name = "故意err";
err.message = "error!";
throw err;
res.status(200).json({msg: 'good!'});
})
app.use(router_err);
第三方中间件
当然了,在实际生产中,并不需要每个中间件都我们自己写,一是自己造轮子麻烦,而是自己造的轮子可用性不高,不够专业,三是优秀团队开发的中间件性能更好,隐患更小
可以更多的使用第三方团队开发的优秀的中间件,比如鉴权相关的passport.js,jsonwebtoken,sql相关的knex,sequelize等等。
万物皆可中间件
上面给的几个例子,都是属于一个模块的不同部分作为中间件挂载到当前的应用,在express.js中,中间件远不止于次
app也可以作为中间件挂载到app!一般是负责不同功能的app聚合到一个总的app上,比如订单模块单独一个app,用户模块单独一个app,一起挂载到作为整个完整系统的app上,这样子把整个系统按不同模块切割成独立的app,更易于维护和管理,有点伪微服务架构的意味。
router也能把app作为他的子中间件,这种做法应该很少用吧,暂时不清楚有什么应用场景。
下一章-架构整合
架构整合
在第一章中,我们按功能分块学习了express后端中不同方面的技术,所有的代码基本都写在了一个文件中,在实际开发中这是不符合规范的,我们需要有一个合理的目录结构,在本章中,将结合常见的前后端架构思想,express.js特性以及借鉴其他语言的优秀框架的架构,每节介绍一种架构方式
注意,这些架构的名字仅仅是我自己这么称呼用的,不代表它们就一定叫这个
express-cli
首先介绍一下express官方的手脚架
搭建
- 创建一个目录
- 进入项目,终端内暗转express
npm install express
- 利用express打架基础项目
express
- 安装基础项目的依赖
npm install
你将获得这样的一个项目,可以通过npm run start运行:
│ app.js
│ package-lock.json
│ package.json
│
├─bin
│ www
│
├─node_modules
├──//...
│
├─public
│ ├─images
│ ├─javascripts
│ └─stylesheets
│ style.css
│
├─routes
│ index.js
│ users.js
│
└─views
error.jade
index.jade
layout.jade
app.js是整个程序的入口文件,package.json是项目配置文件,node_modules是项目依赖,public是存放静态资源的目录,routes是存放我们定义的路由模块的目录,views是渲染层目录(里面的.jade是node.js的一种页面渲染模板),bin是脚本目录
启动脚本
bin目录下的www,其实就是一个写好的脚本,用来挂载express应用并启动服务器的:
引入了app.js,设置了端口,创建了一个服务器,定义了错误监听和成功监听端口时的回调,基本上就这么一些东西
静态目录
public没什么可说的,就存放静态资源的,如果是当作纯后端,就放点图片、LOGO、以及初始化文件之类的,前后端一体的话还多些css和js脚本等
views
一体的前端,渲染模板用的jade,我不会,跳过
routes
专门放定义的路由/接口,我们看其中一个:
写完一个路由,然后导出,就这样
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
module.exports = router;
当然,你也可以不止写一个路由,写成聚合路由集群,或者导出多个也是可以的,一般同属一个小模块的可以放在一个文件里
补充
这个手脚架的结构就这么简单,实际开发中,我们肯定要加添加更多的目录,比如存放类的目录,存放封装好的sql或者工具函数的目录,存放自定义的中间件目录等等
本身express就是个轻量级框架,简单意味着你可以更加自由的组装你的项目结构
下一节-MVC层级架构
MVC层级架构
M-V-C(model-view-control)是非常经典的一种web项目架构,将项目分为模型,视图和控制三大层。
这是我自己搭建的一种mvc架构:
│ app.js
│ package-lock.json
│ package.json
│
├─control
│ ├─routes
│ │ userRoutes.js
│ │
│ └─service
│ userService.js
│
├─model
│ resp.js
│ user.js
│
├─node_modules
│ //...
│
├─static
│ data.json
│
├─utils
│ sqlUtil.js
│ stringUtil.js
├─midwares
│ exhandler.js
│
└─views
index.html
模型:实体类
视图:页面
控制:各种控制(逻辑、视图等)
他们各自还可以细分层次:
model层
所有模块需要的模型都放到这里
model可以按照其用途、服务对象等分成普通对象、数据传输对象、完整对象的散对象、数据表映射对象等等,比如po, dto, vo等等,之前sequelize中的模型就算是数据表映射对象。
当然这是一个跨语言的概念,由于js天生没有类型系统,很多时候你可以选择不定义某些对象,有更高的灵活性,定义对象,虽然灵活性降低,但更易于代码维护,看实际情况决定,当然,一些高复用性的建议定义好,比如给REST接口统一的返回格式,那你就可以专门设定一个对象:
let resp = {
code: null,
msg: null,
data: null,
Ok: (msg,data)=>{
this.code = 200;
this.msg = msg!=undefined? msg : 'success';
this.data = data!=undefined? data : null;
}
}
let respOk = {
code: 200,
msg: 'success',
data: null
}
module.exports = {
resp: resp,
respOk: respOk
}
控制层
所有功能模块的路由,服务等等都放到这里
控制层可以再根据特性分层,比如路由单独搞个routes层,业务处理单独搞个service层等等
补充
同样的,实际开发中需要更多的目录,比如工具目录,资源目录等等,放你的图片,放你的工具函数,放你封装好的sql函数,放你的中间件等等
下一节-基于业务特性的分布式架构
分布式结构
基于业务特性的分布式结构
上节的mvc架构,把所有不同模块的同层文件都放在一个目录下
我们也可以将你的项目结构按照业务模块进行划分,每一个模块内可以再按mvc分层,或者不分,这样子把不同模块独立出来的就叫做分布式结构(dcs)
结构
│ package-lock.json
│ package.json
│ server.js
│
├─assets
│ logo.svg
│
├─goodModule
│ │ app.js
│ │
│ ├─midwares
│ ├─model
│ │ good.js
│ │
│ ├─routes
│ ├─service
│ └─sqls
├─midwares
├─node_modules
│ //...
│
├─orderModule
│ │ app.js
│ │
│ ├─midwares
│ ├─model
│ │ order.js
│ │
│ ├─routes
│ ├─service
│ └─sqls
├─userModule
│ │ app.js
│ │
│ ├─midwares
│ ├─model
│ ├─routes
│ ├─service
│ └─sqls
├─utils
└─views
server.js是整个应用的入口文件,user,good和order分别创建了三个express app,完成各自的业务,最终挂载到server.js中去
下一节-微服务架构
微服务架构
微服务
微服务架构是将一个单体应用程序拆分为一个个独立且保持松耦合的服务的一种架构方式,每个服务有着独立的数据库并且能独立运行部署,所有的服务最终可以被视作一个集群而进行统一管理
优缺点
从微服务的理念着手,它的优缺点绝大部分能通过与单体应用相对比得出
优点
微服务的优点,就是解决了单体应用的痛点
- ★ 高可维护性与高可拓展性
随着时间的推移,单体项目将不可避免的臃肿无比且交错杂乱,高耦合的屎山代码使得每一次维护与拓展都变得胆战心惊。而微服务将完整系统中的每一个模块抽离出来,使得业务更加清晰且耦合度降低,维护与拓展将会容易很多 - ★ 程序构建与迭代高效 原本庞大的单体项目修改了源码之后需要整个项目进行重新编译与运行,如果体量足够大,可是要不少时间。拆分为微服务后,只需要重新编译与运行有限的几个微服务即可,由于微服务的体量小很多并且可以并行构建,效率肉眼可见的高
- ★ 系统稳定与健壮性增强 一体的单体应用中如果某一环出了问题,可能导致整个系统瘫痪的重大事故,而独立且松耦合的微服务系统,完全可以将瘫痪的范围缩小到有限的部分微服务上,而不至于导致整个系统下架维护
- ★ 打破技术限制与瓶颈 毕竟微服务是独立开来的,因此每个微服务完全可以采取不同的语言与开发环境,以适应各自的特色业务需求,比如需要强劲算力的微服务可以采用Rust语言和更快的GPU硬件,需要图形计算的微服务可以使用Neo4j作为数据库等等
缺点
当然了,微服务也是一把双刃剑,在解决了单体服务的痛点的同时,由于分布式的架构不可避免的带了一些原本不存在的挑战
- 运维与部署成本高 单体应用不出意外就一个应用程序和一个数据库,运维和部署是很容易的。虽然微服务的每个独立服务可以通过CI/CD实现自动化构建与部署,但考虑到各个微服务的特性与独立的数据,可能需要多台不同的服务器,配置过程也较为繁琐
- 分布式系统的复杂性 由于微服务架构遵从分布式,这将带来许多挑战与困难,比如系统容错、数据同步、分布式事务、网络延迟等等的问题
- 通信接口维护成本高 微服务之间通过内部的api交互,当其中一个api变动,其他依赖它的服务都需要做出相应的调整
设计原则
- 单一职责原则 微服务各司其职,只关心完整系统中的一部分功能
- 服务自治原则 微服务高度独立,与其他服务保持松耦合状态,在开发、测试、部署的过程中应当能做到独立运行而不强制依赖其他服务
- 轻量级通信机制 微服务之间相互通信,应该通过某些比较便捷且支持跨语言跨平台的手段,比如 Rest Api,比如消息队列等
- 合理粒度原则 合理地划分微服务的粒度,不是说代码量少就等于适合做成微服务,更要业务复杂性的体量以及与其他服务之间的关联程度
技术选型
在微服务落地中,有着一些非常不错的开源框架可供选择
- SpringCloud 一款非常优秀且成熟的微服务开源框架
- Dubbo 阿里开源的一款微服务框架
- Spring Cloud Alibaba 阿里开源的基于SpringCloud的框架
- Open Feign 出自Spring社区的Restful服务通信组件
- Nacos 阿里开源的一款强大的服务注册中心
- Seata 阿里和蚂蚁开源的分布式事务解决方案
- Nginx 高性能http和反向代理服务器
- Docker 实现微服务的容器化部署
- ...
借助已有的优秀开源框架,将帮助我们更好的理解和实践微服务架构。
下一章-evp-express-cli
evp-express-cli
evp-express-cli 是笔者结合自己的实践经验编写的一款 express 手脚架,以一种比较合适的流程构建的 express 架构。
![]()
![]()
![]()
![]()
文档
安装
安装到局部目录
npm i evp-express-cli -D
或者全局安装
npm i evp-express-cli -g
用法
这里是一些示例。
命令
evp-express:
-v,--version: 显示版本-i,--info: 显示详细信息-h,--help: 显示帮助信息new <projectName>: 以一个特定的名字新建项目start: 启动开发服务器clean <path>: 删除指定路径所有文件add <template>: 添加指定的模板或开发工具
新建项目
不提前安装手脚架,直接从 npm 仓库拉取:
npx evp-express-cli new <projectName>
手脚架局部安装时:
npx evp-express new <projectName>
手脚架全局安装时:
evp-express new <projectName>
运行
切换至项目根目录下,通过以下命令运行: 手脚架局部安装时:
npx evp-express start
手脚架全局安装时:
evp-express start
或者直接通过 npm 脚本:
npm run start
或者直接通过 node:
node index
模板
验证
验证中间件位于 /midwares/valider.js
它导出了这些东西:
module.exports = {
validator,
ValidRace,
ValidAll,
ValidQueue,
ValidQueueAll
}
- validator 是 "express-validator"。
- ValidRace 是并发的验证检验链,并抛出最早检验出错误的那个。
- ValidAll 是并发的验证检验链,并抛出全部错误。
- ValidQueue 是串行的验证检验链,并抛出最早检验出错误的那个。
- ValidQueueAll 是串行的验证检验链,并抛出全部错误。
示例:
const { validator, ValidQueue } = require('../midwares/valider');
router.get('/',
ValidQueue([
validator.query('name').trim().notEmpty().withMessage("name cannot be empty"),
validator.query('age').trim()
.notEmpty().withMessage("age cannot be empty").bail()
.isInt().withMessage("age must be Int").bail().toInt()
]),
(req, res, next) => {
res.send(`Hello ${req.query.name}, you are ${req.query.age} years old!`);
});
你将会得到如下结果:
{
"code":500,
"msg":"name cannot be empty",
"data":null,
"symbol":-1,
"type":"Bad Request"
}
数据库
数据库模板使用 mysql 作为默认数据源, mysql2 作为默认数据驱动 和 knex.js作为默认数据库客户端.
你可以引用 knex-sqlClient 通过 const { sqlClient } = require('utils/knex');.
你可以更换任意其它的数据库,驱动和客户端. 但我强烈 建议你不要 删除 utils/knex 因为这个框架使用它去初始化数据库。
更多的配置信息可以在config.yaml找到.
Redis
Redis模板依赖于 redis.js 丙炔不附带身份认证, 如果你需要的话可以修改 utils/redisProxy.
你可以引用 redisProxy 通过 const { instance } = require('utils/redisProxy');. 你可以使用 instance.client 去获取redis客户端实例。
更多的配置信息可以在config.yaml找到.
Auth
认证模板只是安装了 passport.js 你需要自行配置。
RabbitMQ
RabbitMQ模板依赖于 ampqlb.js 并使用 "guest:guest" 作为默认用户.
你可以引用 异步的 rabbitmqProxy 通过 const { instance } = require('utils/rabbitmqProxy');. 你可以使用 instance.conn 去获取 rabbitmq连接实例.你可以使用 instance.channel 去获取rabbitmq的默认通道实例。
注意它是一个promise, 当被在任何地方引用时,请使用异步语法糖去获取实例,或者通过同步流的方式。
const { instance } = require('../utils/rabbitmqProxy');
app.get('/', async(req, res)=>{
const rbmqProxy = await instance;
const { channel: rbmq } = rbmqProxy;
rbmq.sendToQueue("queue", "hello");
})
Or like this:
const RabbitmqProxy = require('../utils/rabbitmqProxy');
app.get('/', async(req, res)=>{
const rbmqProxy = await RabbitmqProxy.instance;
const { channel: rbmq } = rbmqProxy;
rbmq.sendToQueue("queue", "hello");
})
Or like this:
const amqplib = require('amqplib');
const RabbitmqProxy = require('../utils/rabbitmqProxy');
//@type {amqplib.Channel}
let rbmq = null;
RabbitmqProxy.instance.then(rabbitmq=>{
rbmq = rabbitmq.channel;
})
app.get('/', async(req, res)=>{
rbmq.sendToQueue("queue", "hello");
})
更多的配置信息可以在config.yaml找到.
SocketIO
SocketIO模板依赖于 socket.io 并且挂载服务器于 express-http-server 上.
你可以引用 socketioProxy 通过 const { instance } = require('utils/socketioProxy');. 你可以使用 instance.server 去获取 SocketIO 服务器实例。
更多的配置信息可以在config.yaml找到.
Nacos
Nacos模板依赖于 nacos.js 并且默认使用你项目的包名作为服务名。
你可以引用 nacosClient 通过 const { instance } = require('utils/nacosProxy');. 你可以使用 instance.client 去获取 Nacos 客户端实例。
更多的配置信息可以在config.yaml找到.
开发工具
Babel
Babel工具只是安装了基本的依赖和创建了一个配置文件。
你需要更多的自定义它。
Eslint
Eslint工具只是安装了基本的依赖
你需要更多的自定义它。
Jest
Jest工具只是安装了基本的依赖和创建了一个配置文件。此外, package.json's scripts.test 被替换为 "jest",你可以使用Jest进行快速测试通过 "npm test"命令.
你需要更多的自定义它。
Pkg
Pkg工具用于构建可执行的exe程序,输出目录为dist。
package.json's scripts.build 被替换为 "npx pkg . --out-path dist -t node16-win-x64". 你可以进行快速的构建通过"npm build"命令. 默认的编译目标是 node16-win-x64, 你可以在 package.json 中修改它并且你通常需要去Github上下载对应的目标node.
PM2
PM2是一个由node驱动的进程管理器. 框架创建了一个基础的配置文件(ecosystem.consig.js)
你可以更多的自定义它。
资源
框架将assets目录当作资源目录,请不要修改它!
配置
绝大多数配置信息被写在 assets/config.yaml 中. 你可以引用config通过 global.__config 或者 __config.
日志
日志工具位于 /utils/logger.js
异常处理
异常处理中间件位于 /midwares/exhandler.js
导出了两个中间件: 捕捉和日志.
module.exports = {
excatcher: (err, req, res, next) => {
if (err) {
const {code,msg,symbol,data,back} = err.message;
if (back != false && code) {
if (code) {
if (code == 400) {
res.json(Resp.fail(msg, symbol??-1, data??null));
}
if (code == 500) {
res.json(Resp.bad(msg, symbol??0, data??null));
}
} else {
res.json(Resp.bad(err.message));
}
}
next(err);
} else {
next();
}
},
exlogger: (err,req,res,next)=>{
if (logger.level.level <= 10000) {
logger.error(err);
return;
}
logger.error(err.message);
}
}
通常,在捕获全局异常后,默认的是坏响应,但有时候我们不想要坏响应。
throw new Error(JSON.stringify({code:400,msg:"Invalid arguments."});
甚至我们可能不需要返回响应,我们可以把 back 设置为 "false"。
throw new Error(JSON.stringify({code:400,msg:"Invalid arguments.",back:false});
框架只预置了 200 和 400 两个code,你可以自行拓展。
感谢您的使用!😊🥰
下一章-高级进阶
高级进阶
在本章中,将介绍一些比较细节化的项目技巧,尤其是贴合express.js的
全局变量与配置文件
通常我们会将一些项目的配置信息写在一个文件内,然后读入内存并使用。在 express 中使用全局变量有多种方案,我们一起看看有哪些常用的方案
准备工作
拷贝第一节的HelloWorld项目
准备一个Resp.js模块:
module.exports = {
Ok: (...args)=>{
return {
code: 200,
msg: args[0]?args[0]:"Ok",
data: args[1]?args[1]:null
}
}
}
global
在global对象中挂载我们需要全局共享的量,比如我们想要挂载一个全局的config作为整个express应用的配置,就在项目的唯一入口文件(如: index.js, app.js等)的最顶上(优先于任何模块)设置一次:
// index.js
global.config = {
appname: "GlobalVar"
}
/** 更简洁的写法,隐变量,首次被执行到后,会自动挂载到全局
config = {
appname: "GlobalVar"
}
*/
//创建app应用...
这样我们就可以在其它任何地方调用config,比如新建一个router.js挂载到express应用上去
// router.js
const routes = require('express').Router();
routes.get('/global', (req, res, next)=>{
res.send(Resp.Ok("global中的全局变量", {"appname":config.appname}));
});
module.exports = routes;
// index.js
app.use(routes);
如果我们有很多需要全局共享的配置,挤在index.js的上方多少有点不雅观,那我们可以把它们写在一个文件里,然后在index.js最顶上引入一下
// global.js
global.config = {
appname: "GlobalVar"
}
// index.js
require('./global');
**注意:**由于global中的变量是可以直接以变量名xxx调用的,无需global.xxx,如果变量名设置的比较普通,就比如上面的config,甚至更简单的a之类的,很可能跟其它模块中定义的临时变量冲突,造成变量污染,因此在global上挂载变量时取名一定要特殊点,比如:之前的config替换为__config
global.__config = {
appname: "GlobalVar"
}
优点:
- 调用很便捷
缺点:
- 可能变量污染
- 没有代码提示,不心安
module
自定义一个module,存放一些变量,在需要的地方进行引入
比如:我们自建一个config.js
// config.js
module.exports = {
appname: "GlobalVar"
}
在router.js中引入config.js
// router.js
const CONFIG = require('./config');
routes.get('/module', (req, res, next)=>{
res.send(Resp.Ok("config模块当作全局变量", {"appname":CONFIG.appname}));
});
优点:
- 能有代码提示
- 无变量污染
缺点:
- 每次都要引入,比较麻烦
app.set
在 express 的应用设置表中设置应用内的全局变量:
// index.js
app.set("appname", "GlobalVar");
在其它地方调用app,如挂载在app上的router:
// router.js
routes.get('/app', (req, res, next)=>{
res.send(Resp.Ok("app中的'全局'变量", {"appname":req.app.get("appname")}));
});
在挂载在app下的子应用中,调用父app中的设置,当某字段在子应用中没有设置时,会继承父应用中的字段
//subapp.js
const app = require('express')();
const Resp = require('./Resp');
//当子应用没有设置时,会继承父应用中设置的字段
// app.set('appname', "subapp");
app.all('/', (req, res, next) => {
res.send(Resp.Ok("子应用获取父应用中的全局变量", {
appname: req.app.get("appname")
}));
})
module.exports = app;
//index.js
const subapp = require('./subapp');
app.use('/subapp',subapp);
优点:
- 能有代码提示
process.env
在进程的环境变量中挂载全局变量:
//index.js
process.env.appname = "GlobalVar";
在其它地方调用process.env.appname:
// subapp2.js
const app = require('express')();
const Resp = require('./Resp');
app.all('/', (req, res, next) => {
// console.log(app.settings.env);
res.send(Resp.Ok("在process.env上挂载全局变量", {
appname: process.env.appname
}));
})
module.exports = app;
//index.js
const subapp2 = require('./subapp2');
app.use('/process.env',subapp2);
缺点:
- 没有代码提示,不心安
json
以上的方案都是将配置信息写在js文件中的,对于一个正规的项目来说多少有点儿戏,毕竟写在js中的变量是很容易就能被改变的。绝大多数时候,配置信息是需要变化也不允许变化的,我们只需要静态的信息即可。在Js项目中,经常用json文件作为静态配置文件。
新建一个config.json文件:
{
"appname": "GlobalVar"
}
在我们的router中新加一条测试一下,不管你在哪里require,在首次被require之后,修改json文件内容将不会再产生影响
routes.get('/json', (req, res, next)=>{
let configJson = require('./config.json');
res.send(Resp.Ok("json静态配置文件", {"appname":configJson.appname}));
});
json文件不支持注释,如果想要注释,要么曲线救国(加与被备注键相关的键值对),要么使用Json5规范
npm install json5
新建一个config.json5文件:
{
"appname": "GlobalVar" //应用名
}
接着在项目的入口文件中引入register,会挂载到全局:
require('json5/lib/register');
之后require就可以解析json5文件了:
routes.get('/json5', (req, res, next)=>{
let configJson5 = require('./config.json5');
res.send(Resp.Ok("json5静态配置文件", {"appname":configJson5.appname}));
});
yaml
相比.json文件,.yaml(或.yml)文件是更加现在的配置文件,json文件有着严格的格式要求,yaml(yml)书写起来则更加自然
新建一个config.yaml文件:
# 应用名
appname: GlobalVar # 应用名
在nodeJs中读取yaml需要借助fs和js-yaml:
npm install fs
npm install js-yaml
把fs挂载到全局即可(之前的global.js),一般情况下也不会取fs这样的局部变量名,如果需要频繁的操作文件,挂载到全局后会方便很多:
global.fs = require('fs');
在router.js中引入js-yaml并新建一个测试路由:
const yaml = require('js-yaml');
routes.get('/yaml', (req, res, next)=>{
/*Object */
let configYaml = yaml.load(fs.readFileSync('./config.yaml'));
res.send(Resp.Ok("yaml动态配置文件", {"appname":configYaml.appname}));
});
由于是通过fs读取yaml文件的,因此在改变yaml文件中的内容后,访问路由的结果也会变
本文总共介绍了6种方案,在项目具体采用哪种并没有绝对的说法,因地制宜即可。
下一节-错误分类和日志分级
异常分类和日志分级
第一章已经介绍过全局的异常处理了,但之前的做法过于简单,一股脑的捕获并返回。这一节我们将对异常进行细致的分类,并且日志也做标准化的分级。
准备工作
一个基础的 evp-express 项目
NodeJS Error
先了解一下 NodeJS 里面的异常:
JavaScript 异常是由于无效操作或作为 throw 语句的目标而抛出的值。 虽然不要求这些值是 Error 的实例或从 Error 继承的类,但 Node.js 或 JavaScript 运行时抛出的所有异常都将是 Error 的实例。
在 NodeJS 中,所有抛出(throw)的异常都可以被归为通用的 Error,此外还内置了更细分的 AssertionError, SystemError, SyntaxError 等。
Error:
new Error(message[, options])error.cause:引起 error 的根本原因,可以在 new 时的options中加入error.message:错误的描述error.stack:错误栈,产生 error 的位置
异常分类
evp-express 的错误中间件已经把异常分类做好了,分成两部分 excather 和 exlogger,excatcher 捕获并处理异常,exlogger 则记录日志。我们先来看怎么对异常自定义分类。
自定义分类
自定义分类的方法,其实很简单,无非是在抛出的异常上增加用以标识分类的属性即可。我没有选择这种方式,手动抛出时要略微多写几行代码,error.message 是一个描述字符串,我选择抛出自定义异常时,传递的message是一个json字符串,json里面再放置具体描述,分类信息以及其它等等的信息载体。
throw new Error(JSON.stringfy(
code: 400,
msg: "自定义异常1",
back: true
));
接下来看看异常处理器如何处理自定义异常和其它异常。
excatcher
excatcher做了三件事,捕获异常,解析异常和根据策略调取异常处理器。
- 解析异常:首先尝试将 err.message 作为 json 字符串解析,如果能解析,说明是我们自定义的异常,如果解析失败,说明是其它的异常,就当作普通的 Error 处理。
- 处理自定义异常:自定义异常的载体我总共设置了6个属性:code(分类码),msg(描述信息),symbol(业务码/异常码),data(数据),back(是否返回给前端具体描述)和 status(http状态码)。back置非,就返回通用的系统异常错误给前端;back置是,则根据 code(分类码)从异常处理策略中取出对应的处理器处理结果,如果找不到对应的处理器或者 code 没传,就还是返回统一的系统异常给前端。处理完异常之后,把异常再传递给 exlogger 中间件,去记录异常的日志。
- 异常处理策略:在处理不同的异常上,使用了策略模式,增强代码的可维护性。
excatcher: (err, req, res, next) => {
if (err) {
try {
const payload = JSON.parse(err.message);
const {code,msg,symbol,data,back,status} = payload;
if (back != false) {
const handler = exhandleStrategy.get(code);
if ( handler ) { handler(res,msg,symbol,data,status); }
else { res.json(Resp.bad("System Exception")); }
} else {
res.json(Resp.bad("System Exception"));
}
} catch (_) { // cannot be parsed to JSON object => common error
res.json(Resp.bad("System Exception"));
}
next(err);
} else {
next();
}
},
exhandleStrategy:
const exhandleStrategy = new Map();
exhandleStrategy.set(400, (res, ...args)=>{
const [msg,symbol,data,status] = args;
if (status) {
res.status(status).json(Resp.fail(msg, symbol??-1, data??null));
} else {
res.json(Resp.fail(msg, symbol??-1, data??null));
}
});
exhandleStrategy.set(500, (res, ...args)=>{
const [msg,symbol,data,status] = args;
if (status) {
res.status(status).json(Resp.bad(msg));
} else {
res.json(Resp.bad(msg));
}
})
接下来我们看看 exlogger
exlogger
exlogger 进行了一个判断,如果当前日志级别 <= 10000,即 DEBUG,就记录完整的异常信息,否则只记录异常的描述信息。
exlogger: (err,req,res,next)=>{
if (logger.level.level <= 10000) {
logger.error(err);
return;
}
logger.error(err.message);
}
logger是什么呢?这是 log4js 的日志器,让我们来看看utils/logger.js
log4js标准化日志
我们使用 log4js.js 作为日志框架,log4js.configure 配置了 log4js 的基本配置,日志格式,日志方式(输出、文件等)、日志级别等,日志级别从 evp-express 的项目配置信息中读取而得。
const config = require('../config').get();
const log4js = require('log4js');
let logger = log4js.getLogger("");
log4js.configure({
appenders: {
out: {
type: "stdout",
layout: {
"type": "pattern",
"pattern": "[%d{yyyy-MM-dd hh:mm:ss}] %p %m"
}
}
},
categories: {
default: {
appenders: ["out"],
level: config.log4js.level
}
}
})
module.exports = logger;
日志级别总共有 "ALL","TRACE", "DEBUG", "INFO", "WARN", "ERROR", "FATAL"(致命), "MARK", "OFF"(关闭) 这几级(大小写均支持),重要性逐级递增,在当前设置的 level 之下的日志将不会被记录,如日志级别设置为 "INFO",则 logger.all, logger.trace, logger.debug 将不会进行日志记录。
这些文字的级别对应以下数字,依次为 5e-324, 5000, 10000, 20000, 30000, 40000, 50000, 9007199254740992, 1.7976931348623157e+308
日志器当前的级别可由 logger.level 或者 logger.level.levelStr 获取,当前级别对应的数字可由 logger.level.level 获取,不过还是更建议自定义一个数组或者Map,把所有的级别文字按序放入,然后需要的时候根据索引来判断级别的高低。
下一节-数据库初始化
数据库初始化
在软件开发阶段和测试阶段,为了方便调试,我们通常会进行一系列的数据库初始化操作,比如重置数据表,插入记录等等,或者在部署阶段进行数据初始化的操作
根据前面章节介绍过的 knex.js 和 sequelize.js,我们可以利用它们提供的方法进行DDL,本节就数据库表重置的初始化行为做一点探讨,表结果为User{id: num, name: string, age: num},数据库采用sqlite
Knex DDL
以下是利用 knex.schema 的一个简单示例:
knex.js
const knex = require('knex');
const fs = require('fs');
const sqlClient = knex({
client: 'sqlite3',
connection: {
filename: `${__root}/db/data.db`,
acquireConnectionTimeout: 1000
},
useNullAsDefault: true
});
module.exports = sqlClient;
init.js
global.__root = __dirname;
const knex = require('./knex.js');
const drop = knex.schema.dropTableIfExists('user');
const create = knex.schema.createTable('user', (user)=>{
user.increments('id').notNullable().primary();
user.text('name').notNullable();
user.integer('age').notNullable()
});
const promises = [drop,create];
Promise.all(promises)
.then(res=>{
console.log('Database inits successfully!')
}).catch(err=>{
console.error(err);
})
Sequelize DDL
以下是利用 Sequelize.Model 的一个简单示例:
sequelize.js
const { Sequelize,DataTypes,Model } = require('sequelize');
const fs = require('fs');
const sqlClient = new Sequelize({
dialect: 'sqlite',
storage: `${__root}/db/data.db`
})
const User = sqlClient.define('User', {
id: {
primaryKey: true,
type: DataTypes.INTEGER,
allowNull: false,
autoIncrement: true
},
name: {
type: DataTypes.STRING,
allowNull: false
},
age: {
type: DataTypes.INTEGER,
allowNull: false
}
}, {
tableName: 'user',
timestamps: false,
});
module.exports = {
sqlz: sqlClient,
User
}
init.js
global.__root = __dirname;
const { User } = require('./sequelize');
// User.drop();User.sync();
User.sync({ force: true }) //这个相当于前两个的结合体
.then(res=>{
console.log('Database inits successfully!');
}).catch(err=>{
console.error(err);
})
SQL文件
Springboot作为Web后端最流行的框架之一,想必各位都接触过或者听说过,在Springboot中,可以在配置文件中设置sql脚本的路径,在项目启动时执行sql脚本来完成初始化。 这是一种非常好的方法,因为有时候我们项目场景下的数据库表结构与关系可能非常复杂,而且不同语言,不同框架的实现有些区别,用代码去完成初始化操作将是一件非常麻烦的事,既然SQL是关系型数据库通用的语言,那我们就可以通过SQL脚本来定义数据库表的结构和关系,可以手写SQL脚本,也可以借助如Navicat之类的工具设计表然后转储sql脚本,然后交给我们的程序去执行,或者手动执行。
Node的sql框架千千万,我在几个主流框架中似乎都没看到有提供执行sql文件的特性,其实没那么复杂,不从构造完美的框架角度,仅以为项目服务的角度考虑来说是这样的,接下来我们就来简单实现一下通过sql脚本去初始化数据库。
有两条路:
- 运行环境先安装sqlite3客户端,node读取sql脚本内容,node通过
exec去指定目录下,打开sqlite3命令行连接sqlite数据库,同时把sql内容传递过去,在sqlite3中执行sql脚本完成数据库初始化操作 - Node安装sqlite3依赖,通过sql框架连接sqlite数据库,node读取sql脚本内容,对内容进行规范化处理只剩下纯净的sql语句后,交给sql框架以sql语句的形式去运行
Springboot采用的就是第2种方法,那我们也在Node中实现一下吧
实现准备好sql脚本 schemal.sql:
-- 先删除user表
DROP TABLE IF EXISTS `user`;
-- 定义表结构,并创建user表
CREATE TABLE `user` (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, --自增主键
name TEXT NOT NULL,
age INTEGER NOT NULL
);
Knex
先用Knex作为sql框架做个示范。获取到项目根目录路径后,建立数据库连接: knex.js
const knex = require('knex');
const fs = require('fs');
const sqlClient = knex({
client: 'sqlite3',
connection: {
filename: `${__root}/db/data.db`,
acquireConnectionTimeout: 1000
},
useNullAsDefault: true
});
module.exports = sqlClient;
接下来,为客户端实现执行sql文件的方法:
- 定义
runSql方法的传参和返回
我这里传入sql文件的路径,返回sql语句执行的promise链 - 内部实现,首先通过
fs模块读取sql脚本内容并转为字符串 - 把内容中的注释去掉
- 去掉内容首尾的空格
- 去掉
\r - 去掉
\n(我为了打印sql语段时更加美观,省去了这一步,不影响执行结果) - 把内容按照
;号分割成一个个独立的sql语句字串 - 过滤掉空字串(由每2个sql语句间的空格形成)
sqlClient.runSql = (path)=>{
const script = fs.readFileSync(path).toString();
console.log("Going to run a sql file:");
console.log(script);
/**
* 拆成一句句sql来执行是因为,knex执行一串语句时,会把它们都算进一个事务内
* 利用正则忽略注释
* 去首尾空格
* 按冒号分句
* 校验字串是否为sql语句
* @type {string[]}
*/
const sqls = script.replace(/\/\*[\s\S]*?\*\/|(--|\#)[^\r\n]*/gm, '').trim().replaceAll('\r','').split(';').filter(str=>{
return str.trim() ? true : false;
});
console.log("sqls");
console.log(sqls);
console.log("start run:");
const promises = sqls.map(sql=>{
sql += ';'; // knex会自动补上冒号,加不加无所谓其实
console.log("Going to run a sql:");
console.log(sql);
return sqlClient.raw(sql);
})
return promises;
}
到这里,我们就得到了纯净的一条条sql语句,接下来把sql语句丢给knex即可:
init.js
global.__root = __dirname;
const knex = require('./knex.js')
const promises = knex.runSql(`${__root}/db/schema.sql`);
Promise.all(promises)
.then(res=>{
console.log("Database inits successfully!")
}).catch(err=>{
console.error(err);
})
输出结果:
D:\Workstation\gitee-localRepo\express-demo\DatabaseInit>node index.js
Going to run a sql file:
-- 先删除user表
DROP TABLE IF EXISTS `user`;
-- 定义表结构,并创建user表
CREATE TABLE `user` (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, --自增主键
name TEXT NOT NULL,
age INTEGER NOT NULL
);
sqls
[
'DROP TABLE IF EXISTS `user`',
'\n' +
'\n' +
'CREATE TABLE `user` (\n' +
' id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, \n' +
' name TEXT NOT NULL,\n' +
' age INTEGER NOT NULL\n' +
')'
]
start run:
Going to run a sql:
DROP TABLE IF EXISTS `user`;
Going to run a sql:
CREATE TABLE `user` (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER NOT NULL
);
Server is ready on http://:::8080
Database inits successfully!
很好,我们可以很清晰的看到sql的执行过程
Sequelize
如果你把knex这套照搬过去,把knex.raw换成sequelize.query,你也许会尴尬的发现,不太对劲,它先创建了user表,接着又把它给删了,还大言不惭地打印了成功信息(我的环境下是这样,不清楚别人会不会,但既然发生了就说明存在一定的问题)。尝试反复执行knex示例和seuelize示例,前者永远正确,后者永远错误,而且sequelize似乎更慢一点,产生这样的区别,可能是它们执行sql语句的实现机制不太一样,花费精力去看它源码没有必要,既然在这个场景下我们这两个步骤有着明确的先后顺序,那我们就通过async/await让它们完全的顺序执行即可:
sqlClient.runSql = async (path)=> {
const script = fs.readFileSync(path).toString();
console.log("Going to run a sql file:");
console.log(script);
/**
* 拆成一句句sql来执行是因为,knex执行一串语句时,会把它们都算进一个事务内
* 忽略注释
* 去首尾空格
* 按冒号分句
* 校验字串是否为sql语句
* @type {string[]}
*/
const sqls = script.replace(/\/\*[\s\S]*?\*\/|(--|\#)[^\r\n]*/gm, '').trim().replaceAll('\r','').split(';').filter(str=>{
return str.trim() ? true : false;
});
console.log("sqls");
console.log(sqls);
console.log("start run:");
for (let sql of sqls) {
const res = await sqlClient.query(`${sql};`);
}
}
输出结果:
D:\Workstation\gitee-localRepo\express-demo\DatabaseInit>node index.js
Going to run a sql file:
-- 先删除user表
DROP TABLE IF EXISTS `user`;
-- 定义表结构,并创建user表
CREATE TABLE `user` (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, --自增主键
name TEXT NOT NULL,
age INTEGER NOT NULL
);
sqls
[
'DROP TABLE IF EXISTS `user`',
'\n' +
'\n' +
'CREATE TABLE `user` (\n' +
' id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, \n' +
' name TEXT NOT NULL,\n' +
' age INTEGER NOT NULL\n' +
')'
]
start run:
Server is ready on http://:::8080
Executing (default): DROP TABLE IF EXISTS `user`;
Executing (default): CREATE TABLE `user` (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER NOT NULL
);
Database inits successfully!
Ok!现在Sequelize也按照我们的意愿完成了重置user表的初始化工作
如果初始化过程中涉及严格的先后顺序,务必做好同步流甚至回滚机制。此外,在实际项目中,为了项目的代码规范性,应当将数据库路径,初始化脚本路径都写在配置文件中,而不是像本节为了方便直接写在需要调用的js文件中。
下一节-页面渲染
页面渲染
常见的页面分为两种,一种是静态页面,比如用 Vue、React 等写好的静态页面,另一种是动态模板页面,如 Thymeleaf,JSP 等。
本节将简要介绍如何在 express 中渲染静态页面,以及适用于 express 的模板引擎 pug 。
配置开放资源
写前端的和搞部署的同学应该都清除,页面渲染的用到的 css, js, fonts, images 等都是静态资源,部署的时候需要在服务器端放行并配置一个正确的路径。
Express 内置了一个 static 中间件来托管静态资源:express.static(root, [options])
大致用法如下:
app.use(URL, express.static(PATH));
URL是外界访问静态资源的前缀路径,PATH则是资源资源目录的位置,可以是相对路径也可以是绝对路径。
渲染静态页面
为了方便演示,我用 evp-express-cli 快速创建了一个 express 后端,并使用 Svelte 快速构建了一个简单的页面,而且已经构建好了,构建产物就在svelte/public目录。
为了方便和模板页面区分,我决定把静态目录设为public,并让我们的静态页面展示在 /static 路由下
- 拷贝静态页面到我们准备开放的public下面
- 配置静态页面获取资源的路径
原本的css,js等等路径都是在
/下的,我们调整到/static/下面去
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset='utf-8'>
<meta name='viewport' content='width=device-width,initial-scale=1'>
<title>Svelte app</title>
<link rel='icon' type='image/png' href='/static/favicon.png'>
<link rel='stylesheet' href='/static/global.css'>
<link rel='stylesheet' href='/static/build/bundle.css'>
<script defer src='/static/build/bundle.js'></script>
</head>
<body>
</body>
</html>
- 在 express 中设置静态资源路径,src\app.js
app.use('/static', express.static(path.join(__dirname, '../public')));
- 此时运行后端,访问 static 路由即可正常显示我们的静态 svelte 页面
其它的前端框架 Vue、React 等都是类似的,就不介绍了。
模板引擎 pug
可以用的模板引擎有很多,express 官方推荐了 pug,那我们就用 pug吧
还是在刚才那个项目,先安装 pug 依赖:
npm install pug
这次,我打算让 pug 页面渲染在 /views/ 路由下,在根目录创建一个 views 目录
- 在 app.js 中设置页面引擎为 pug
app.set('view engine', 'pug');
- 在
/views路由上渲染pug页面
app.get('/views', (req,res)=> {
res.render('index', { title: 'express-pug-demo', message: 'Welcome to express pug!'});
})
后面的是我们给 pug 模板传递的参数,既然是动态页面了,自然要体验一下数据交互 3. 在 views 目录下创建index.pug 和 css目录 4. 在 index.pug 中写页面,传进来的参数相当于全局变量,可以直接引用;我们还自定义了一个常量,放到 a 标签上,并引入了 css/index.css 作为页面样式
- const express_demo = 'https://jun-laner.gitee.io/express-demo'
doctype html
html
head
title= title
style
include css/index.css
body
div(class="container")
h1= message
a(href= express_demo, target= '_blank') Go to express-demo
- css目录下创建 index.css 并写入样式
.container {
text-align: center;
padding-bottom: 28px;
}
此时重启服务器,并访问 views 即可正常渲染 pug 页面
pug 用法简介
接下来,我们简要介绍一下 pug 的语法(可以直接拉取本节的源码并运行,pug的用法都写在了示范的pug页面中)
标签
在 html 中的标签在 pug 中不能加书名号了,并且会自闭和,无须手动闭合,如: html:
<p>
hello, world!
</p>
pug:
p hello, world!
需要注意的是,html中因为标签是闭合的,所以标签上下、标签之间可以不严谨的对齐,但是 pug 标签必须对齐,排列在它应该排列的列范围内,缩进了才代表这个标签囊括在上一级标签下。
文档类型
Doctype,通常我们指定为 html 即可,其实就是 html 文件的头
doctype html
html
//...
定义变量
在 pug 中我们可以写 js 脚本,定义变量,然后嵌入到标签中去渲染
- const hello_msg="Welcome to express pug!
//...
span #{hello_msg}
把变量赋给标签内容,可以像上面那种模板嵌入,也可以直接赋予
span= hello_msg
代码块
如果你的 js 代码很长,不方便写在一行,比如定义一个数组
错误示范,这样子是错误的,这是单行脚本的写法
- const list = [
"a",
"b",
]
正确示范,空出一行即可:
-
const list = [
"a",
"b",
]
标签属性
通常我们需要给标签赋予一些属性,比如元素的类名、a 标签的地址、图片的地址等等
a(href= express_demo, target= "_blank") Go to express-demo'
多个属性用逗号分隔开,变量直接赋给属性,硬编码的属性则以字符串传入
列表渲染
通常我们会需要渲染列表,vue 中有 v-for,React用 map 迭代列表,而 pug 可以用 each in 直接迭代列表
- const apps = [{ name: "qq" },{ name: "wechat" },{ name: "ins" }]
each app in list
p #{app.name}
注意缩进,迭代的元素要缩进到 each 下级
If 分支
如果遇到需要条件渲染的地方,可以这样写
if hello_msg
span hello_msg exists!
Case 分支
如果有条件有多个值,可以用 case 来替换 if
- const day = 1;
case day
when 1
span Monday
default
span Unknown
引入外部文件
学过 JSP 的应该记得 JSP 里面就有 include,pug 的include 可以引入一个 pug,引入其它文件则会被当作文本
我们可以用 include 来导入外部CSS:
html
head
title= title
style
include css/index.css
如果你想用 link 的方式导入CSS,也可以,但 express 后端必须把对应目录设置为静态资源
html
head
title= title
link(rel='stylesheet', href='css/index.css') //- 如果要href引入,必须在express中设置为静态资源
设置 views 为资源目录:
app.use('/views', express.static(path.join(__dirname, '../views')));
样式
上面已经介绍从外部引入样式办法,这里再补充一下在 pug 中如何直接写样式:
style.
h1 {
color: green;
}
style标签后面的那个 . 不要忘记,剩下的样式就按常规的CSS写法即可
过滤器
过滤器可以用于渲染特定的片段,需要借助插件实现,当然也可以自定义
以渲染 markdown 为例,先安装 markdown 依赖
npm install jstransformer-markdown-it
然后划定一块区域,放置我们的markdown
div(class="md")
:markdown-it(linkify langPrefix='highlight-js')
# Markdown
use markdown in pug file
## example
this is example
# Thanks For Reading this Article
页面渲染就介绍到这里,重要的静态资源配置,模板页面通常其实用不到,如果需要,更详细的用法可以关注 pug 官方手册
下一节-express-validator
express-validator
express.js 集成 express-validator进行数据校验
在最初的时候,对于请求的数据校验,我们是自定义一个中间件,然后在里面通过最原生的方式检验。在本节,我们将尝试用一种更优雅的方式进行数据校验。
准备工作
创建一个基础的 express 项目(本文基于evp-express-cli),并支持全局同步和异步错误错误处理。
安装express-validator,并引入:
npm i express-validator
const validator = require('express-validator');
验证链
validator:
- body()
- cookie()
- header()
- param()
- query()
以validator.query为例,我们可以检查query参数中的某一项
router.get('/greet',
validator.query('person').trim().notEmpty().escape().withMessage("person不能为空"),
(req, res, next) => {
const valires = validator.validationResult(req);
if (!valires.isEmpty()) {
const err = new Error(valires.array()[0].msg);
throw err;
}
logger.info(`Hello ${req.query.person}!`);
res.send(`Hello ${req.query.person}!`);
});
validationResult()用法获取校验结果,valires是校验结果,主要结构如下:
{
//...
errors: []
}
errors需要通过valires.array()来得到,当然序列反序列化也行 每一项error结构如下:
{
"type": string,
"msg": string,
"path": string, //如上面检查的person
"location": string //如query,body..
}
如果需要检验多个参数,就放进数组即可:
[
validator.query('person').trim().notEmpty().escape().withMessage("person不能为空"),
validator.query('address').trim().notEmpty().escape().withMessage("address不能为空")
]
封装剥离
之前的写法,是把错误处理和定义都直接写在路由上,臃肿且代码侵入性较强,我们可以进一步封装:
Checker:
这个示例采取了检验并发竞赛的机制,你也可以使用其它的并发或者同步机制:
/**
* Validator Race checker
* @param {validator.ValidationChain[]} validChain
* @returns
*/
const ValidRace = (validChain)=>{
return async (req, res, next) => {
await Promise.race(validChain.map(validate => validate.run(req)))
const valires = validator.validationResult(req);
if (!valires.isEmpty()) {
console.log(valires.array());
const err = new Error(valires.array()[0].msg);
throw err;
}
next();
}
}
然后在路由上使用即可:
router.get('/greet2',
ValidRace([
validator.query('age').trim()
.notEmpty().withMessage("age不能为空").bail()
.isInt().withMessage("age必须是正整数").bail().toInt()
]),
(req, res, next) => {
logger.info(`Hello ${req.query.person}!`);
res.send(`Hello ${req.query.person}!`);
});
bail()的用处是,如果前面出错就终止检验链,不加的话,age空了还会往后面检验是不是整数。
当然你也可以赋给一个变量,然后再引进来:
const CheckGreet2 = ValidRace([
validator.query('age').trim()
.notEmpty().withMessage("age不能为空").bail()
.isInt().withMessage("age必须是正整数").bail().toInt()
]);
router.get('/greet2', CheckGreet2, (req, res, next) => {
logger.info(`Hello ${req.query.person}!`);
res.send(`Hello ${req.query.person}!`);
});
express-validator的用法远远不止于此,详见官方文档https://express-validator.github.io/docs
下一节-使用zod检验
使用zod检验
上一节我们介绍了 express-validator,本节我们介绍一个更通用的检验工具 Zod
What's Zod.js?
写前端的同学可能知道Zod,我们在提交表单前需要对数据初步检查,Zod是一个很棒的工具。前端可以偷懒,但后端不能偷懒,Zod也可以用到我们的 express 后端中来,封装一个 Zod 中间件即可
准备工作
用 evp-express-cli 创建一个最简洁的新项目。
了解Zod工作流程
- 定义待检验的数据格式
const { z } = requie("zod");
const schema = z.object({
username: z.string().nonempty("username cannot be empty")
})
这个 schema 就是 Zod 检验一个对象或者变量的检验器,如果检验目标只是一个值,z.string()之类的即可
2. 检验器验证传入
把待检查的数据传递给检验器,有4种:schema.parse(data), schema.parseSync(data), schema.safeParse(data), schema.safeParseSync(data),parse会直接抛出错误信息,而safeParse返回一个对象,包含了验证是否成功和错误信息,结构如是:{success: boolean, message: ZodError}
3. 错误处理
对于检验器发现的错误你需要自行处理
安装Zod
npm install zod
封装中间件
在 midwares 目录下创建 zod.js:
导出了一个 ZodValid函数:该函数传入一个对象,包含了 headers, params, query 和 body 四个可选属性,分别对应请求可以传入数据的四个部分,如果需要检验,就传入定义好的检验器给需要检验的部分;ZodValid会返回一个 request handler,在处理器里面根据传入的检验器分别去进行检验,这个处理器才是最后的中间件,ZodValid其实是一个中间件工厂。我在这里取出了第一个错误,并将错误的 message 抛出,evp-express 默认直接捕捉并返回错误信息,我这样写是为了让读者对错误信息能看的更清楚,非特定场景下,不一定要返回这样细致的错误信息,可以抛出统一错误信息。
const { z } = require("zod");
/**
* @typedef {{
* code: string;
* expected: string;
* received: any;
* path: string[];
* message: string;
* }} MyZodError
*/
/**
* @param {z.ZodError} errors
* @reutrns
*/
function selFirstError(errors) {
/**
* @type {MyZodError[]}
*/
const errs = JSON.parse(errors);
return errs[0];
}
module.exports = {
/**
*
* @param {{
* headers: z.ZodObject|undefined;
* params: z.ZodObject|undefined;
* query: z.ZodObject|undefined;
* body: z.ZodObject|undefined;
* }} param0
* @returns
*/
ZodValid: ({headers, params, query, body})=>{
/**
* @type {import("express").RequestHandler}
*/
const handler = (req,res,next)=>{
if (headers) {
const result = headers.safeParse(req.headers);
if (!result.success) {
throw new Error(selFirstError(result.error).message)
}
}
if (params) {
const result = params.safeParse(req.params);
if (!result.success) {
throw new Error(selFirstError(result.error).message)
}
}
if (query) {
const result = query.safeParse(req.query);
if (!result.success) {
throw new Error(selFirstError(result.error).message)
}
}
if (body) {
console.log(req.body);
const result = body.safeParse(req.body);
if (!result.success) {
throw new Error(selFirstError(result.error).message)
}
}
next();
}
return handler;
}
}
使用中间件
改写 router/index.js:定义2个路由,一个 GET 一个 POST,GET接口检验 query 参数种的 name 字段,POST接口检验请求体数据中的 name, pass 和 email,由于请求发送的数据格式使用了 Json,所以我们的ZodValid要放在转换请求体格式的Json中间件之后。
const { Router } = require('express');
const logger = require('../utils/logger');
const Resp = require('../model/resp');
const { ZodValid } = require('../midwares/zod');
const { z } = require('zod');
const { Json } = require('../midwares/bodyParser');
const router = Router();
router.get('/', ZodValid({
query: z.object({ name: z.string().nonempty("name cannot be empty") })
}), async (req, res, next) => {
const name = req.query.name;
logger.info(`Hello World! ${name}`);
res.json(Resp.ok(`Hello World! ${name}`, 1, null));
});
router.post('/', Json, ZodValid({
body: z.object({
name: z.string().nonempty("name cannot be empty").min(8, "name at least 8 length"),
pass: z.string().nonempty("password cannot be empty").min(8, "password at least 8 lenght"),
email: z.string().email("email is invalid") })
}), async (req, res, next) => {
const name = req.body.name;
logger.info(`Hello World! ${name}`);
res.json(Resp.ok(`Hello World! ${name}`, 1, null));
});
module.exports = router;
测试
调整请求数据,分别访问这两个接口,你将得到类似这样的结果:
{
"code": 500,
"msg": "name cannot be empty",
"data": null,
"symbol": 0,
"type": "Bad Request"
}
{
"code": 500,
"msg": "email is invalid",
"data": null,
"symbol": 0,
"type": "Bad Request"
}
本文仅演示了 Zod.js 最基础的用法,还有z.optional可选,z.nullish可空,z.refine自定义逻辑等api,更详细更高阶的用法可以查看 Zod官方手册:https://zod.dev/README_ZH
下一节-集成Redis
集成Redis
本节我们介绍在 express.js 中集成 redis.
Redis是一个高性能的key-value内存数据库,支持事务、队列、持久化等特性,常用于高并发性能场景。
准备工作
- 创建一个 express.js 项目(本文基于evp-express-cli)
- 在开发环境下安装redis
- 安装redis.js:
npm i redis
创建代理
正常的项目都是分层的,为了避免循环依赖,本文采用代理类构造单例的方式来创建redis连接。
redisProxy.js:
在构造器内创建redis连接,并监听个别事件,最后把连接赋给client成员变量。再定义一个静态的获取实例方法,调用时实例若为空,就构建实例:
const Redis = require('redis');
const logger = require('./logger');
class RedisProxy {
/**
* @type {RedisProxy}
*/
_instance = null;
constructor() {
const client = Redis.createClient({
url: `redis://127.0.0.1:6379`,
});
client.on('connect', () => {
logger.info('Redis connected!');
});
client.on('error', err => {
logger.error('Redis Client Error!', err);
process.exit(1);
});
client.connect();
this.client = client
}
static instance() {
if(!this._instance) {
this._instance = new RedisProxy();
}
return this._instance;
}
}
然后把redis导出来:
async function init() {
return RedisProxy.instance();
}
module.exports = {
init,
instance: RedisProxy.instance(),
};
然后在任意其它地方调用 redisProxy.instance 即可获取单例,在从单例中获取client即可操作redis.
const RedisProxy = require('../utils/redisProxy');
const redisProxy = RedisProxy.instance;
const redis = redisProxy.client;
redis.set("name", "evpantchouli"); //设置键
console.log(await redis.get("name"); //取键
你可以自己手动配置一遍,也可以使用evp-express-cli作为手脚架创建项目并选择redis模板。
关于redis.js的详细用法请见官方文档: http://npmjs.com/package/redis
下一节-集成RabbitMQ
集成RabbitMQ
本节我们介绍在 express.js 中集成 rabbitmq.
RabbitMQ 是一个消息队列中间件,常用于请求削峰,事务的队列处理,事件订阅机制的实现等。
准备工作
- 创建一个 express.js 项目(本文基于evp-express-cli)
- 在开发环境下安装rabbitmq
- 安装amqplib.js:
npm i amqplib
创建代理
正常的项目都是分层的,为了避免循环依赖,本文采用代理类构造单例的方式来创建ampqlib连接。
redisProxy.js:
在构造器内创建redis连接,并监听个别事件,最后把连接赋给client成员变量。再定义一个静态的获取实例方法,调用时实例若为空,就构建实例:
const amqplib = require('amqplib');
const logger = require('./logger');
class RabbitmqProxy {
/**@type {RabbitmqProxy}*/
_instance = null;
/**@type {amqplib.Connection}*/
conn;
/**@type {amqplib.Channel}*/
channel;
static async instance() {
if (!this._instance) {
let ins = new RabbitmqProxy();
const conn = await amqplib.connect({
username: `guest`,
password: `guest`,
hostname: `127.0.0.1`,
port: `5672`,
});
logger.info("Connected to RabbitMQ!");
ins.conn = conn;
const channel = await ins.conn.createChannel();
//确认队列
channel.assertQueue("hellos");
//订阅队列
channel.consume("hellos", async (message) => {
console.log("hello, two!");
channel.ack(message); //报告处理完毕
});
ins.channel = channel;
this._instance = ins;
}
return this._instance;
}
}
amqplib创建rabbitmq连接是异步的,所以获取实例的静态方法也是异步的,如果你想转为同步函数,只能通过进程阻塞的方式实现。上面给我们的rabbitmq客户端订阅了一个hellos队列。
然后把rabbitmq导出来:
async function init() {
return RedisProxy.instance();
}
module.exports = {
init,
instance: RedisProxy.instance(),
};
然后在任意其它地方调用 await rabbitmqProxy.instance 即可获取单例,在从单例中获取conn和channel即可操作rabbitmq.
const rabbitmqProxy = require('../utils/rabbitmqProxy');
app.post('/', async(req,res,next)=>{
const rbmqproxy = await rabbitmqProxy.instance;
const channel = rbmqproxy.channel;
//发送消息到"hellos"队列
channel.sendToQueue("hellos", "hello!");
res.send();
})
你可以自己手动配置一遍,也可以使用evp-express-cli作为手脚架创建项目并选择rabbitmq模板。
关于amqplib.js的详细用法请见官方文档: http://npmjs.com/package/amqplib
下一节-集成Websocket
集成websocket
本节我们介绍在如何在 express 中集成 websocket。
WebSocket 服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话,属于服务器推送技术的一种。
准备工作
- 创建一个 express.js 项目(本文基于evp-express-cli)
- 安装ws.js:(本教程使用更通用的ws.js,有兴趣的同学可以去了解express-ws.js)
npm i ws
创建代理
正常的项目都是分层的,为了避免循环依赖,本文采用代理类构造单例的方式来创建websocket服务器。
wsProxy.js:
在构造器内创建websocket服务器,并监听个别事件,最后把服务器赋给server成员变量。再定义一个静态的获取实例方法,调用时实例若为空,就构建实例:
const {WebSocketServer} = require('ws');
class WebsocketProxy {
/**@type {WebsocketProxy} */
static INSTANCE;
server;
constructor() {
const _server = new WebSocketServer({
server: require('./server')
})
this.server = _server;
_server.on("listening", () => {
console.log(`websocket server is listening.`);
})
_server.on("connection", (ws) => {
console.log(`websocket client connection`);
ws.send(`Hello, I'm WebSocket server.`);
ws.on("message", (message) => {
ws.send(`${message}`);
})
})
}
static instance() {
if(!WebsocketProxy.INSTANCE) {
WebsocketProxy.INSTANCE = new WebsocketProxy();
}
return WebsocketProxy.INSTANCE;
}
}
function init() {
return WebsocketProxy.instance();
}
module.exports = {
init
};
最后把服务器导出来:
async function init() {
return WebsocketProxy.instance();
}
module.exports = {
init,
instance: WebsocketProxy.instance(),
};
然后在任意其它地方调用 wsProxy.instance 即可获取单例,在从单例中获取server即可主动操作websocket.
const WsProxy = require('../utils/wsProxy');
const wsProxy = WsProxy.instance;
const wsServer = wsProxy.server;
你可以自己手动配置一遍,也可以使用evp-express-cli作为手脚架创建项目并选择websocket模板。
关于 ws.js 的详细用法请见官方文档: https://www.npmjs.com/package/ws
下一节-集成SocketIO
集成SocketIO
本节我们介绍在如何在 express 中集成 Socket.IO
Socket.IO 算是 WebSocket 的一个超集,进行了一些封装和拓展。
准备工作
- 创建一个 express.js 项目(本文基于evp-express-cli)
- 安装socket.io.js:
npm i socket.io
创建代理
正常的项目都是分层的,为了避免循环依赖,本文采用代理类构造单例的方式来创建websocket服务器。
wsProxy.js:
在构造器内创建socket.io服务器,并监听个别事件,最后把服务器赋给server成员变量。再定义一个静态的获取实例方法,调用时实例若为空,就构建实例:
const { Server } = require('socket.io');
const server = require('./server');
const logger = require('./logger');
class SocketIoProxy {
/**
* @type {Server}
*/
_instance = null;
constructor() {
this.server = new Server(server);
logger.info('SocketIo server created!');
this.server.on('connection', (socket) => {
socket.on('message', (data) => {
logger.info(`client: ${JSON.stringify(data)}`);
socket.emit('message', data);
});
});
}
static instance(){
if(!this._instance){
this._instance = new SocketIoProxy();
}
return this._instance;
}
}
async function init() {
return SocketIoProxy.instance();
}
module.exports = {
init,
instance: SocketIoProxy.instance()
}
最后把服务器导出来:
async function init() {
return SocketIoProxy.instance();
}
module.exports = {
init,
instance: SocketIoProxy.instance(),
};
然后在任意其它地方调用 socketioProxy.instance 即可获取单例,在从单例中获取server即可主动操作socketio.
const SocketioProxy = require('../utils/socketioProxy');
const socketioProxy = SocketioProxy.instance;
const socketioServer = socketioProxy.server;
你可以自己手动配置一遍,也可以使用evp-express-cli作为手脚架创建项目并选择socketio模板。
关于 socket.io 的详细用法请见官方文档: https://socket.io/zh-CN/
下一节-全面鉴权
全面鉴权
这一节我们来介绍一下 Passport.js,这是一个强大的 NodeJS 的认证中间件
Passport.js 提供了多种认证方式,账号密码、OpenID、ApiKey、JWT、OAuth、三方登录等等。
使用 Passport.js 认证要配置三个部分:
- 认证策略
- 中间件
- 会话
接下来我们以 账号密码 认证为例,来演示一下 Passport.js 的使用
准备工作
新建一个基础的 evp-express 项目
安装依赖
- 安装 passport.js
npm install passport
- 安装 local 策略
npm install passport-local
创建页面
在 public 目录下面创建 index.html, fail.html, home.html 3个页面:
index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form action="/login" method="post">
<input name="username" placeholder="username..." />
<input name="password" placeholder="password..." />
<button type="submit">Login</button>
</form>
</body>
</html>
fail.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Fail</title>
</head>
<body>
<h1>Fail</h1>
<a title="gologin" href="/views">Go login</a>
</body>
</html>
home.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Home</title>
</head>
<body>
<h1>Hello, Home!</h1>
</body>
</html>
设置静态目录
app.js:
const config = require('./config.js').get();
//...
app.use('/views', express.static(config.public, { extensions: ['html'] }));
这个 extensions 选项用于允许访问静态页面不带 html 后缀。
开启Session
app.js:
//...
app.use(session({
secret: 'secret',
resave: false,
saveUninitialized: true
}));
初始化passport
app.js:
const passport = require('passport');
//...
app.use(passport.initialize());
app.use(passport.session());
设置认证
步骤:
- 使用策略,规定认证过程,done是回调函数,可以接收三个参数:
- 异常
- 在会话中保存的用户信息,填 false 代表认证失败
- 其余数据,比如传递信息
- 序列化用户信息
- 反序列化用户信息 app.js:
const LocalStrategy = require('passport-local').Strategy;
//...
passport.use(new LocalStrategy(
function verify(username, password, done) {
if (username == 'root' && password == 'root') {
return done(null, { username, password});
}
return done(null, false, {message: "None"});
}
))
passport.serializeUser((user, cb) =>{
process.nextTick(()=>{
cb(null, {username: user.username, password: user.password})
})
})
passport.deserializeUser((user, cb) => {
process.nextTick(()=>{
return cb(null, user);
});
});
编写登录接口
router/index.js:
const { Json, Form, Multi, FromPlus } = require('../midwares/bodyParser');
//...
router.post('/login', FromPlus, passport.authenticate('local', {
failureRedirect: '/views/fail',
failureFlash: false
}), (req, res, next) => {
res.redirect('/views/home');
});
前端页面在表单中填写登录信息,先按照表单格式解析一下,然后再加入 passport 的认证中间件,指定策略为 local, 并指定认证失败跳转到 fail.html,成功则重定向到 homte.html,这个可以和失败重定向一样,作为 successRedirect 选项写到上面。
保护接口
编写一个判断时候登录的中间件函数:
function isLogined(req, res, next) {
if (req.isAuthenticated()) {
return next();
}
res.redirect('/views/');
}
对 / 路由进行登录保护:
router.get('/', isLogined, (req, res, next) => {
logger.info('Hello World!');
res.json(Resp.ok('Hello World!', 1, null));
});
测试
此时运行项目,在浏览器中访问http://127.0.0.1:8080,会被重定向到登录界面,登录成功后在地址栏可以正常访问到这个被保护的路由,登录失败则会被重定向到 fail 页面。
Passport.js 的更多用法请自行探索,详见官方文档:https://www.passportjs.org/docs/
下一节-软件测试
软件测试
本节介绍如何在 express.js 使用 Jest 进行单元测试
准备工作
- 准备一个基础的 express 项目,本文基于 evp-express-cli
- 安装 Jest
npm install jest --save-dev
- 生成 Jest 配置
npx jest --init
编写测试
创建测试文件,以 .test.js 后缀命名,Jest 在运行期间会自动查找并执行符合 *.test.js 命名的文件,为规范起见,新建一个 test 目录,存放所有的测试文件。
编写第一个测试
- 先准备一个要被测试的函数
sum(a, b),写在src/uitls/index.js中:
module.exports = {
/**
* Return the result of the sum of a and b.
* @function
* @param {number} a
* @param {number} b
* @returns {number}
*/
sum: (a, b) => {
return a + b;
}
}
- 在
test目录下创建sum.test.js,引入sum并编写测试代码:
const { sum } = require('../src/utils');
describe('test demo', () => {
test('sum test', () => {
expect(sum(1, 2)).toBe(3);
})
})
toBe() 可以简单得判断相等,类似于 assertEqual,Jest 的具体语法本文不做介绍,自行查阅,其它测试框架如 mocha.js 的语法也是类似的。
3. 执行测试
npx jest
得到结果:
PASS test/sum.test.js
test demo
√ sum test (2 ms)
----------|---------|----------|---------|---------|-------------------
File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
----------|---------|----------|---------|---------|-------------------
All files | 100 | 100 | 100 | 100 |
index.js | 100 | 100 | 100 | 100 |
----------|---------|----------|---------|---------|-------------------
Test Suites: 1 passed, 1 total
Tests: 1 passed, 1 total
Snapshots: 0 total
Time: 0.58 s, estimated 1 s
对路由进行测试
现在我们尝试对路由进行测试,先安装 supertest:
npm install supertest --save-dev
在 test 目录创建 router.test.js,引入 express app 和 supertest:
const request = require('supertest');
const app = require('../src/app');
接着争对 src/router/index.js 中定义的 / 路由进行测试:
describe('router test', () => {
it('GET /', () => {
request(app).get('/')
.expect('Content-Type', /json/)
.expect(200)
.then(res => {
expect(res.body).toStrictEqual({
ok: true,
msg: 'Hello World!',
data: null,
symbol: 1,
type: 'Ok'
});
}).catch(err => console.error(err));
})
})
toStrictEqual 用于判断对象的严格相等;对路由测试需要用到 supertest 传入 app,然后对其 / 路由发起 GET 请求,因为请求过程是异步的,所以对响应结果的测试写在 then 回调中,当然你也可以把测试函数写成 async-await 语法糖;这个路由不需要传递任何数据,如果你需要携带数据,可以使用 send (x-www-form-urlencoded), set (请求头), field (multipart-form)等,具体用法请自行查阅 supertest 文档。
接下来执行测试:
npx jest
得到结果:
PASS test/sum.test.js
PASS test/router.test.js
---------------|---------|----------|---------|---------|------------------------------
File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
---------------|---------|----------|---------|---------|------------------------------
All files | 62.93 | 60 | 30 | 62.93 |
src | 71.76 | 66.66 | 100 | 71.76 |
app.js | 100 | 100 | 100 | 100 |
config.js | 66.66 | 66.66 | 100 | 66.66 | 36-59
src/midwares | 30.18 | 100 | 0 | 30.18 |
exhandler.js | 30.18 | 100 | 0 | 30.18 | 7-12,16-22,26-43,47-52
src/model | 50 | 0 | 0 | 50 |
resp.js | 50 | 0 | 0 | 50 | 4-10,19-25,29-31,35-37,41-43
src/router | 83.33 | 100 | 100 | 83.33 |
index.js | 83.33 | 100 | 100 | 83.33 | 8-9
src/utils | 100 | 100 | 100 | 100 |
index.js | 100 | 100 | 100 | 100 |
logger.js | 100 | 100 | 100 | 100 |
---------------|---------|----------|---------|---------|------------------------------
Test Suites: 2 passed, 2 total
Tests: 2 passed, 2 total
Snapshots: 0 total
Time: 2.054 s
Ran all test suites.
[2023-08-06 18:43:20] INFO Hello World!
如果你只想执行 router.test.js,则在后边指定要执行的测试文件即可:
npx jest test/router.test.js
下一节-软件构建
软件构建
运行node项目,一般都是直接运行源码,不过这样子部署的时候不太方便,需要拷贝整个文件夹,如果是需要交付给客户的,并且客户不需要源码,客户不懂编程知识的话,你丢给他一堆源码让该怎么让他运行呢?Java可以打包成 jar/war, C/C++可以打包为 exe,Node也迫切需要一种可靠的构建技术。前端的朋友们可能都熟悉webpack,rolliup或者是Vite,不过它们都只是将项目合并为单个js文件,运行仍旧依赖外部的js-runtime,在本节,我们将介绍一个构建Node项目为可执行程序的工具 —— pkg
准备工作
创建如下项目目录:
│ package.json
│ readme.md
│
├─assets
│ config.yaml
│
├─db
│ data.db
├─src
│ index.js
│
├─dist
│
└─node_modules
assets目录放的是静态资源,比如配置,图片,脚本什么的,我这里放一个yaml配置文件:
app:
name: pkg-demo
version: 0.0.1
server:
host: 127.0.0.1
port: 8080
db目录则放置我们的sqlite数据库文件
以下是index.js的内容:
做了3件事情,连接到sqlite数据库,提供返回config.yaml内容的接口和下载数据库文件的接口
const express = require('express');
const evchart = require('js-text-chart').evchart;
const app = express();
const path = require('path');
const yaml = require('js-yaml');
const fs = require('fs');
const config = yaml.load(fs.readFileSync('../assets/config.yaml'));
const dbpath = '../db/data.db';
const knex = require('knex');
const sqlite = knex({
client: 'sqlite3',
connection: {
filename: dbpath,
acquireConnectionTimeout: 1000
},
});
app.all("*", function (req, res, next) {
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "Content-Type");
res.header("Access-Control-Allow-Methods", "*");
res.header("Content-Type", "application/json;charset=utf-8");
next();
});
app.get('/', function (req, res) {
res.send('Hello World!');
});
app.get('/config', function (req, res) {
res.json(config);
});
app.get('/db', function (req, res) {
res.download(dbpath);
});
const server = app.listen(config.server.port, config.server.host, () => {
let host = server.address().address;
let port = server.address().port;
let str = config.app.name;
let mode = [ "close", "far", undefined ];
let chart = evchart.convert(str, mode[0]);
console.log(chart);
console.log("Server is ready on http://%s:%s", host, port);
})
此时我们访问这些接口都是可以正常用的:
C:\Users\GrapeX>curl -X GET http://127.0.0.1:8080
Hello World!
C:\Users\GrapeX>curl -X GET http://127.0.0.1:8080/config
{"app":{"name":"pkg-demo","version":"0.0.1"},"server":{"host":"127.0.0.1","port":8080}}
接下来,我们就来实现把这个小项目构建为一个可以直接运行的exe程序,并且assets内置其中,db则还是在外边,方便我们管理数据库
安装并配置pkg
安装pkg: npm i pkg -dev
大致说一下pkg是怎么进行构建的:首先指定项目的入口js文件,然后pkg会根据代码中的依赖关系,顺藤摸瓜的把所有相关的js文件都找到,然后根据指定的node版本和编译平台环境(win,linux,macos)开始编译你写的js文件和项目安装的依赖模块,最终构建exe程序
pkg构建命令的结构:pkg 入口文件 [options]
可以通过 pkg --help 查看命令选项:
Options:
-h, --help output usage information
输出使用帮助信息
-v, --version output pkg version
输出 pkg 版本信息
-t, --targets comma-separated list of targets (see examples)
以逗号分隔的目标列表(参考示例)
-c, --config package.json or any json file with top-level config
package.json 或者任何 json 文件顶层配置
--options bake v8 options into executable to run with them on
将 v8 选项打包到可执行文件中,以便它们一起运行
-o, --output output file name or template for several files
输出文件名或者多个文件的输出模板,默认为npm-package-name
--out-path path to save output one or more executables
保存输出可执行文件的路径
-d, --debug show more information during packaging process [off]
在打包过程中展示更多信息,默认关闭
-b, --build don't download prebuilt base binaries, build them
不下载预构建的基础二进制文件,而是构建它们
--public speed up and disclose the sources of top-level project
加速和公开顶级项目的源代码
--public-packages force specified packages to be considered public
强制指定包被认定为公开的
--no-bytecode skip bytecode generation and include source files as plain js
跳过字节码生成阶段,直接打包源文件为普通 js
--no-native-build skip native addons build
跳过原生插件构建
--no-dict comma-separated list of packages names to ignore dictionaries. Use --no-dict * to disable all dictionaries
以逗号分隔的包名列表忽略字典,使用 --no-dict * 禁用所有字典
-C, --compress [default=None] compression algorithm = Brotli or GZip
压缩算法 Brotli 或者 GZip. 默认关闭
最核心的几个选项是:
-t:必须要指明编译的依据,否则将会是默认的,比如v16.16.0-linux-x64--out-path:通常我们都会将构建产物生成在指定的目录下-o:不填将默认为package.json中的name或入口文件名,往往我们可能希望是其它的名字
要注意的是 -o 和 --out-path 不能同时设置,只能设置其中一个
打包
对我们的项目进行基础的打包,指定入口为index.js,node版本为16,平台为64位Windows,输出路径在dist目录:
pkg index.js node16-win-x64 --out-path=dist/
或者在 package.json中添加 bin 选项:
{
"bin": "index.js"
}
然后使用.替代,pkg此时会去读取package.json中的bin:
pkg index.js node16-win-x64 --out-path=dist/
运行这条命令,你会看到pkg在拉取(fetch) node16-win-x64,不出意外的话,你半天都拉不下下来,因为它们的服务器在境外
我们可以到 Github: https://github.com/vercel/pkg-fetch/releases 上去手动下载对应的fetch包,注意版本要和你使用的 pkg 版本契合,我当前的 pkg 版本是3.4,所以我选取了 v3.4 中的 node-v16.16.0-win-x64,下载到本地后,进入 C:\Users\{你用户}\.pkg-cache\你版本\目录,拷贝下载好的文件到这里,并把node改成fetched,这样pkg下构建时就会使用事先下载好的node源了
构建好了,我们双击运行index.exe一下,很好,直接闪退,我们打命令index.exe > log.txt 看看:
node:internal/fs/utils:345
throw err;
^
Error: ENOENT: no such file or directory, open './assets/config.yaml'
at Object.openSync (node:fs:585:3)
at Object.openSync (pkg/prelude/bootstrap.js:793:32)
at Object.readFileSync (node:fs:453:35)
at Object.readFileSync (pkg/prelude/bootstrap.js:1079:36)
at Object.<anonymous> (C:\snapshot\pkg\index.js)
at Module._compile (pkg/prelude/bootstrap.js:1926:22)
at Object.Module._extensions..js (node:internal/modules/cjs/loader:1159:10)
at Module.load (node:internal/modules/cjs/loader:981:32)
at Function.Module._load (node:internal/modules/cjs/loader:822:12)
at Function.runMain (pkg/prelude/bootstrap.js:1979:12) {
errno: -4058,
syscall: 'open',
code: 'ENOENT',
path: './assets/config.yaml'
}
报错是找不到对应的文件或目录,它找不到我们的config,yaml,此时我们把assets目录复制到dist下,可以正常运行,相同的,db也要复制过来,才能正常下载data.db文件。但这并不是我们想要的,因为我们想要的是配置文件内置在exe程序中,因为往往会包含一些敏感信息。
配置内置资源目录
当我们需要将静态资源,比如配置文件(.yaml,.json等)或者其它的非.js文件,需要事先设置资源,pkg才会把指定的资源打包进exe中
配置方法是在 package.json 中配置 pkg:assets 选项:
"pkg": {
"assets": [
"assets**/*"
]
},
assets接收一个数组,每个元素是你指定的资源路径,可以使用通配,上面这个就是把assets下所有文件都指定为资源文件
官方文档给了这么个示例:
"pkg": {
"scripts": "build/**/*.js",
"assets": "views/**/*",
"targets": [ "node14-linux-arm64" ],
"outputPath": "dist"
}
scripts是指那些额外编译后的js,比如你用了大量高级esm语法的代码,被你用babel编译成的普通js,比如你用了v8的然后被编译好的js等等
配置好后再运行,此时还是不行,哪一步出问题了?原因在于我们的路径是这么写的,这种形式会以读取外部文件的方式去寻找:
fs.readFileSync('../assets/config.yaml');
而pkg构建的exe是一个快照程序,运行时将处于系统快照内,你可以看到index.js实际运行于C:\snapshot\pkg\index.js,所以对于项目内的资源路径,必须基于快照,快照路径可以用__dirname获取
const config = yaml.load(fs.readFileSync(`${__dirname}/assets/config.yaml`));
如果采取使用path模块规范化路径,甚至可以不配置package.json,因为pkg检测到path+__dirname时会自动把对应路径当成资源对待:
path.join
fs.readFileSync(
path.join(
__dirname,
'../assets/config.yaml')
)
path.resolve也行
fs.readFileSync(
path.resolve(
__dirname,
'../assets/config.yaml')
)
到这里,exe完美的如期运行!
正确的读取外部路径
但是呢,我们的代码依旧存在小小的瑕疵,就是我们的数据库路径:
const dbpath = '../db/data.db';
开发的时候是在根目录下,但部署的时候?打包完后,外部的文件路径可都是相对于exe来说的,也就是说db要放到部署目录的上级目录了,这不符合常理。所以在配置外部文件路径时,我们应当基于根目录去写。怎么获取根目录?index.js中读取__dirname?在pkg中行不通的,因为__dirname已经成为项目内的虚拟路径了
正确的做法是 process.cwd(),这个命令可以直接获取到项目根目录路径(入口文件路径):
const dbpath = `${process.cwd()}/db/data.db`;
或者用path规范化路径:
const dbpath = path.join(process.cwd(), './db/data.db');
压缩
在构建的时候还可以指定--compress参数,来减小构建产物的体积,如:
pkg . -t node16-win-x64 --compress GZip --out-path=dist/
本节的示例项目exe由原先的46MB缩小到了40MB,压缩效果还行,不过毕竟压缩了,多多总会对程序的性能造成一点影响,如果你的项目有较高的性能需求,请慎重考虑是否压缩
其它
关于--no-bytecode参数,开启的话,构建的时候pkg不会将js转为二进制,而是直接以js打包进exe内,体积会小一点,不过js源码的运行效率自然会比二进制程序要逊色一点。
es6+
此外,如果你使用了一些es6+的模块,如axios,pkg构建时会报错,--no-bytecode参数可以逃避构建时的报错,但这是治标不治本,运行照样跑不通。
我的建议是,使用这些依赖预编译好的普通js版本(axios的package.json似乎写的有点问题,可以手动把代码拷出来用),如果没有你就手动用babel编译,或者直接使用它们的老的普通js的版本,如 axios 0.27.2 及以前的。
以Axios为例
现在新增一个/toConfig接口,该接口用axios请求之前的/config接口并返回响应结果:
const axios = require('axios').default; //pkg打包失败
app.get('/toConfig', function (req, res) {
axios.get(`http://${config.server.host}:${config.server.port}/config`)
.then(function (resp) {
res.json(resp.data);
})
});
直接用 pkg 构建会出错,因为 pkg 基于 CommonJs 模块,而新版的 axios 默认导出的是 ESModule
- 方案1:拷贝axios.cjs
拷贝node_modules\axios\dist\node\axios.cjs放到自己的源码下并引用:
const axios = require("./axios.cjs").default; // 方案1
此时,把原先的axios依赖删了都行,pkg构建的时候还不会WARN
- 方案2:把axios.cjs作为资源脚本
const axioscjs = path.join(__dirname,"../node_modules/axios/dist/node/axios.cjs");
const axios = require(axioscjs).default; // 方案2
pkg构建的虽然会WARN,但能正常运行即可
- 方案3:使用低版本的 axios
npm uninstall axios && npm i axios@0.27.2
版本低了,比较旧,可能存在不少潜在的问题,不太推荐使用
下一节-Docker部署
Docker部署
本节我们来介绍如何使用 Docker 部署 express 应用
准备工作
- linux 系统
- 安装好 Docker
- 一个基础的 evp-express-cli 项目,选上 pkg 工具包
- Docker 的详细用法本文不做介绍,请先自行查阅了解
在 Docker 中部署源码
一个很简单的部署方法就是,拉取一个 node 基础镜像,直接在里面运行 express 项目:
以下是 .dockerignore 示例:
node_modules
dist
以下是响应的 Dockerfile 示例:
# Build environment
FROM node:16
ENV NODE_ENV=production
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 8080
CMD ["node src/index.js"]
基本流程就是:
- 拉取node镜像
- 指定工作目录
- 拷贝项目源码及资源文件
- 安装依赖
- 暴露端口
- 设置启动命令
在 Docker 中构建部署
上面采取的是直接部署源代码,当然也可以先对源码进行构建再部署。这里又可以分为两种,一种仍然需要 node 运行时,仅仅借助 rollup 之类的工具将源码打包为单个 .js 文件,然后部署时只需拷贝这单个文件即可,具体过程无需再做介绍
另一种是脱离 node 运行时,使用 pkg 构建 express 项目,最终部署构建产物到纯净的 linux 镜像即可。如果你在进行 docker 部署前,事先构建好再部署,那具体做法也不需介绍,本文介绍的是在 docker 中阶段的从零构建到部署的过程:
编写 Dockerfile:
- 拉取合适的 node 镜像作为构建环境,
builder是构建镜像别名,可以随便取(后面有用):
# Build environment
FROM node:16 AS builder
ENV NODE_ENV=production
- 拷贝依赖配置文件(
package.json和package-lock.json*)到指定目录(后面有用)
WORKDIR /app
COPY ["package.json", "package-lock.json*", "./"]
- 安装依赖包
RUN npm install
- 拷贝源码以其它要一并被打包进可执行程序的文件
ADD src src
ADD assets assets
- 构建适用于linux的可执行程序,示例的产物名为
DockerDeploy(后面有用)
RUN npm run build:linux
- 拉取一个 linux 镜像作为运行环境,示例选用了 debian,具体能用哪个还要视项目而定
# lightly runtime environment
FROM debian
- 设置时区,如果需要的话
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
RUN echo 'Asia/Shanghai' >/etc/timezone
- 从构建镜像将中构建好的可执行程序拷贝到到运行镜像下的指定目录
语法:
COPY --from=构建镜像别名 可执行程序路径 指定目录路径
COPY --from=builder /app/dist/DockerDeploy /app/
- 拷贝外部的资源文件和文件夹(如果有的话),示例没有,略过,如有,用
ADD或COPY即可 - 暴露端口,并在指定目录下运行可执行程序
WORKDIR /app
EXPOSE 8080
CMD ["./starfolder-service"]
以下是完整的 Dockerfile 示例:
# Build environment
FROM node:16 AS builder
ENV NODE_ENV=production
WORKDIR /app
COPY ["package.json", "package-lock.json*", "./"]
RUN npm install
ADD src src
RUN npm run build:linux
# lightly runtime environment
FROM debian
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
RUN echo 'Asia/Shanghai' >/etc/timezone
COPY --from=builder /app/dist/starfolder-service /app/
WORKDIR /app
EXPOSE 8080
CMD ["./DockerDeploy"]
这样的分阶段构建过程,可以尽可能得减小最终的镜像体积
下一节-pm2进程管理
pm2进程管理
本节我们将介绍如何使用 pm2 运行和监管我们的 express 项目
准备工作
- 一个 express 项目
- 全局安装 pm2
npm install -g pm2
pm2使用介绍
启动应用
你可以用纯命令去运行一个node项目,假设原本运行项目使用 node src/index.js可以跑起来一个项目,则:
pm2 start -name "pm2-node-app" node -- src/index
当然你还可以通过将部分信息写到配置文件中,文件可以是 js, json 等,js格式的可以通过以下命令生成:
pm2 init
这将得到一个名为 "ecosystem.config.js" 的文件,内容如下:
module.exports = {
apps : [{
script: 'index.js',
watch: '.'
}, {
script: './service-worker/',
watch: ['./service-worker']
}],
deploy : {
production : {
user : 'SSH_USERNAME',
host : 'SSH_HOSTMACHINE',
ref : 'origin/master',
repo : 'GIT_REPOSITORY',
path : 'DESTINATION_PATH',
'pre-deploy-local': '',
'post-deploy' : 'npm install && pm2 reload ecosystem.config.js --env production',
'pre-setup': ''
}
}
};
deploy那部分是构建,在本节我们仅将 pm2 用于项目的运行管理,无需关注构建。重点是 apps 列表,每一个元素分别对应一个应用的配置信息,包括启动时运行的脚本命令(script),文件变动监控(watch)等
热重载
假设我们的源码入口位于 "src\index.js",我们需要开发时热重启项目(仅src内文件变动):
module.exports = {
apps : [{
script: 'src/index.js',
watch: ['src']
}]
};
pm2根据这个文件去运行应用时可以直接这样:
pm2 start // 与ecosystem.config.js同目录
如果你使用其它的配置文件,如 json,配置的格式也是类似的,则需要向pm2指明该配置文件名,如:
pm2 start app.json
管理应用
pm2 stop <id|name|namespace|all|json|stdin>:停止指定的应用pm2 restart <id|name|namespace|all|json|stdin>:重启指定的应用pm2 reload <id|name|namespace|all|json|stdin>:即刻重载web应用pm2 delete <id|name|namespace|all|json|stdin>:删除指定的应用
应用监控
pm2 ls:终端中查看所有应用状况pm2 monit:打开终端的监控面板pm2 plus:在浏览器中的Dashboard,使用pm2 plus可能会报错,可以直接访问网址https://app.pm2.io/
查看日志
pm2 log:查看所有应用日志pm2 log <id|name|namespace|all|json|stdin>:查看指定日志
应用集群
你可以将一系列应用划分到一个命名空间内作为一个集群,通过指定namespace,进行全体的重启等操作。 以 ecosystem.config.js 为例,这一组应用包含了2个 node 应用:
module.exports = {
apps : [{
name: 'express-app1',
script: './app1/src/index.js',
watch: './app1/src',
namespace: 'express-demo'
}, {
name: 'express-app2',
script: './app2/src/index.js',
watch: './app2/src',
namespace: 'express-demo'
}]
};
关于 pm2 更多的使用技巧,还请诸君自行探索
下一章节-最佳实践
代码规范
编程规范,对于一个优秀的项目是不可或缺的,有了良好的代码规范,有益于项目的维护与拓展。
命名规范
命名的第一要义是明了,要让阅读者看到命名就能大概猜测出其意义或用处。
以用户身份(userRole)为例,不可过度简略为 "ur",本身这个单词也不算长,拼全 "userRole" 即可,或者 "uRole",因为字母 "u" 通常代表用户,这是约定俗成的。
命名规范可以跟据被命名的目标再细分:
变量命名:
可变变量通常用 let 声明,命名时可以采取首字母小写的驼峰(userRole)或者小写蛇形命名法(user_role);常量变量通常用 const 声明,命名时通常采用全大写(USERROLE)或者大写蛇形命名法(USER_ROLE)
函数命名: 独立的函数或者作为成员变量的方法,命名通常采取首字母小写的驼峰(checkUserRole)小写蛇形命名法(check_user_role)
类命名:
类、接口或者一系列函数和变量的聚合引入的命令通常采用大写驼峰命令法(User),对其内部私有的量或者方法,由于 js 和 ts 都不存在真正意义上的 private,所以在私有量或方法前加上 _ 短下划线即可,意指这是私有的。此外,在声明类或对象拥有的属性和方法时,要避免冗余的前缀,比如:
class User {
userLogin() {
//...
}
}
以上代码的 "userLogin" 就是典型的前缀冗余。
文件命名:
文件命名通常采用小写驼峰命名(strUtil.js)或者小写点隔式命名(str.util.js),小写蛇形命名法也不是不行,但在 js 项目中较为罕见。
排版规范
一个统一且整洁的排版也是相当重要的,比如:
- 统一的 4空格 或者 2 空格缩进,符号后 1 空格缩进
const sayHi = () => {
console.log('Hi, Express Learner!');
}
- 同行内逗号分隔后的 1空格缩进
- 单文件内不同性质或不同阶段的代码用单空行相隔
- 引入依赖或其它文件通常写在文件顶部
- 函数多参数下放
function add_10_nums(
a1: number, b1: number,
a2: number, b2: number,
a3: number, b2: number,
a4: number, b2: number,
a5: number, b2: number)
{
return //...
}
- 多行对齐
等等...
注释规范
合适的注释有助于自己和他人快速理解并维护一段代码,写注释不必事事具细,比如在意义很明显的 login() 函数上加 // 登录函数 这么一句代码,只需要在比较复杂或者仅靠命名和表面的调用关系即可推断出作用的代码上进行适当的注释即可。此外,现在的主流 IDE 对注释都支持 markdown,可以适当地利用 markdown 语法进行注释增强。
切记注释是给人看的,别把注释格式写的难以阅读,比如长篇大论且挤在一行上。
此外通过注释的 JsDoc 可以对函数的参数、返回,对象的属性等进行类型标注和解释,合理的运用 JsDoc 注释,将使得我们在不使用 TypeScript 的情况下也能获得良好的代码提示。
下一节-高性能
高性能
在生产环境下,真实的访问流量远超测试与开发环境,而且往往是不稳定的访问。以下是有助于提高你的 Express 应用性能的一些建议。
设置生产环境
NODE_ENV 环境变量指定运行应用程序的环境(通常是开发或者生产环境)。为了改进性能,最简单的方法是将 NODE_ENV 设置为 "production":
env NODE_ENV=production
将 NODE_ENV 设置为“production”会使 Express:
- 高速缓存视图模板。
- 高速缓存从 CSS 扩展生成的 CSS 文件。
- 生成简短的错误消息。
测试表明仅仅这样做就可以使应用程序性能提高 3 倍多!
多使用异步函数
同步函数和方法会阻止执行进程的运行,直至其返回。每一次同步函数的执行可能只会阻塞几毫秒,但当大量的请求同时发生时,这些同步函数的阻塞将直接累加,这是非常可怕的(不行你可以试试)。
压缩响应体
通过 Gzip 压缩,有助于显著降低响应主体的大小,从而提高 Web 应用程序的速度。可使用压缩中间件进行 Express 应用程序中的 gzip 压缩。例如:
const compression = require('compression');
const express = require('express');
const app = express();
app.use(compression());
对于生产环境中的大流量网站,实施压缩的最佳位置是在反向代理层级。在此情况下,不需要使用压缩中间件。有关在 Nginx 中启用 gzip 压缩的详细信息,请参阅 Nginx 文档中的 ngx_http_gzip_module 模块。
使用负载均衡
无论应用程序如何优化,单个实例都只能处理有限的负载和流量。扩展应用程序的一种方法是运行此应用程序的多个实例,并通过负载均衡器分配流量。设置负载均衡器可以提高应用程序的性能和速度,并使可扩展性远超单个实例可以达到的水平。
负载均衡器通常是逆向代理,用于编排进出多个应用程序实例和服务器的流量。可以使用 Nginx 或 HAProxy 轻松地为应用程序设置负载均衡器。
其实 pm2 也自带负载均衡作用。
高速缓存
提高生产环境性能的另一种策略是对请求的结果进行高速缓存,以便应用程序不需要为满足同一请求而重复执行操作。
可以把热点数据以及通用信息放在 redis 之类的缓存数据库中,将有助于性能的提升。
高可用自动重启
尽管有诸多措施,难免有时候流量势不可挡而导致服务崩溃,这时候自动重启的机制就显得尤为重要,可以使用 pm2 之类的进程管理器来实现这个机制。
下一节-安全性
安全性
在 Web 应用中,安全亦是相当重要的一环,在正式的场景下,数据安全尤为重要。
使用高稳定版本的 Express
Express 2.x 和 Express 3.x 已不再维护,其中存在的安全性和性能问题不会得到修复,请尽可能的使用或迁移到 Express 4.x
使用 TLS
如果应用需要处理或传输敏感数据,请使用 TLS 来保护连接和数据,TLS 在客户端发起阶段对其加密,从而防止初步的黑客行为。
使用 Helmet
helmet.js 是一个 Express 中间件,用于设置 HTTP 标头来帮助 Express 应用免受一些常规的 Web 漏洞:
CSP设置标头以防止跨站脚本攻击和注入,Content-Security-PolicyhidePoweredBy删除X-Powered-By标头hsts设置强制与服务器建立安全连接(https)Strict-Transport-SecuritynoCache和Pragma禁用客户端缓存Cache-ControlnoSniff设置以防止浏览器从声明内容类型嗅探响应的 MIMEframe设置以防止点击劫持X-Frame-OptionsxssFilter设置以禁用 XSS 缺陷脚本X-XSS-Protection
使用方法:
npm install helmet --save
挂载到 app:
const helmet = require("helmet")();
app.use(helmet);
安全地使用 Cookie
为确保 Cookie 不会打开您的应用而受攻击,请不要使用默认 Cookie 会话名称:
const Session = require("express-session");
app.set("trust proxy", 1);
app.use(Session({
secret: 'express-demo',
name: 'sessionX'
}));
此外,设置一些安全选项来确保 Session 安全:
app.use(Session({
name: "sessionX",
keys: ["evp-key-1", "evp-key-2"],
cookie: {
secure: true,
httpOnly: true,
domain: 'express-demo.com',
path: 'security',
expires: new Date(Date.now() + 60 * 60 * 1000) // 1 hour
}
}));
争对暴力攻击的端点保护
如争对同一用户或同一IP的短期内大量失败行为进行监测,进行适当的用户封禁和IP封禁。
rate-limiter-flexible 提供了相关的技术支持,文档详见此处
确保依赖安全
您正在使用的 npm 包也许存在安全漏洞,你可以使用 npm audit 来分析依赖树,并通过 npm audit fix 进行简单的修复,如果你想要更精细的控制依赖安全,可以尝试一下 snyk.js:
- 安装
npm install -g snyk
- 检测漏洞
synk test
- 引导修复
synk wizard
其它注意事项
以下是优秀的 Node.js 安全检查表中 的一些进一步建议。有关这些建议的所有详细信息,请参阅该博客文章:
- 使用 csurf 中间件防止跨站点请求伪造(CSRF)。
- 始终筛选和清理用户输入,以防止跨站点脚本 (XSS) 和命令注入攻击。
- 使用参数化查询或预准备语句防御 SQL 注入攻击。
- 使用开源 sqlmap 工具检测应用中的 SQL 注入漏洞。
- 使用 nmap 和 sslyze 工具测试 SSL 密码、密钥和重新协商的配置以及证书的有效性。
- 使用安全正则表达式确保您的正则表达式不容易受到正则表达式拒绝服务攻击。
下一节-健康检查
健康检查
许多时候,我们需要对应用进行监控,来获取他的详细状态,这节介绍几个在 express 中进行健康检查的方案。
亲自手写
亲自创建一些路由,根据情况返回应用的相关信息,不过自己写比较麻烦,除非有特别的需求,一般我们就用第三方的解决方案。
express-actuator
express-actuator.js 是一个现成的用于 express 的健康检查中间件:
npm install express-acutator --save
配置express-actuator:
在你的主应用中引入 actuator 即可:
const actuator = require('express-actuator');
const app = express();
app.use(actuator({
basePath: '/actuator',
infoGitMode: 'simple',
// infoBuildOptions: null, // extra information you want to expose in the build object. Requires an object.
// infoDateFormat: null, // by default, git.commit.time will show as is defined in git.properties. If infoDateFormat is defined, moment will format git.commit.time. See https://momentjs.com/docs/#/displaying/format/.
customEndpoints: [] // array of custom endpoints
}));
其中有一些配置选项:
- basePath: actuator的基路由,如果不设置,则其所有路由("/info", "health", "metrics")将挂载在 app 的路由上
- infoGitMode: 暴露的Git信息, 'simple' 或者 'full'
- infoBuildOptions: 额外暴露的信息
- infoDateFormat: Git提交信息的时间格式
- customEndpoints: 自定义端点(初始仅提供了"/info", "health", "metrics")
访问端点:
- "/info":会包含你的项目信息(从 package.json 读取)和Git信息,如:
{
"build": {
"description": "This is my new app",
"name": "MyApp",
"version": "1.0.0"
},
"git": {
"branch": "master",
"commit": {
"id": "329a314",
"time": "2016-11-18 08:16:39-0500"
}
}
}
- "/metrics":express 应用的健康详情,如:
{
"mem": {
"rss": 39350272,
"heapTotal": 11038720,
"heapUsed": 8889952,
"external": 892742,
"arrayBuffers": 32982
},
"uptime": 58.3234052
}
- "/health":当下的健康状况,如:
{
"status": "UP"
}
lightship
lightship.js 也是一个不错的健康检查工具,并且可以与 Kubernetes 集成:
npm install lightship --save
不过与 express-actuator 不同的是,express-actuator是挂载在 express 应用上的中间件,而 lightship 是自己单独开辟一个 http 服务器(即额外占用一个端口):
async function start() {
const config = require('./config').get();
const init = require('./init');
await init();
const express = require('express');
const jsTextChart = require('js-text-chart');
const logger = require('./utils/logger');
const server = require('./utils/server');
const Lightship = await import('lightship');
const createLightship = Lightship.createLightship;
const app = require('./app');
const lightship = await createLightship({
detectKubernetes: false,
port: 8081,
// gracefulShutdownTimeout, // 优雅停机时间
// gracefulShutdownTimeout, // 优雅停机延迟
// shutdownHandlerTimeout, // 停机Handler时间
// signals, // An a array of [signal events]{@link https://nodejs.org/api/process.html#process_signal_events}. Default: [SIGTERM].
// terminate // Default: `() => { process.exit(1) };`
});
server.on('request', app);
server.listen(config.app.port, config.app.host, async() => {
let host = server.address().address;
let port = server.address().port;
let str = config.app.name;
let mode = [ "close", "far", undefined ];
let chart = jsTextChart.convert(str, mode[0]);
console.log(chart);
console.log("Server is ready on http://%s:%s", host, port);
lightship.registerShutdownHandler(() => {
lightship.shutdown();
server.close();
})
lightship.signalReady();
});
}
start();
其中有一些配置选项:
- detectKubernetes 是否探查 Kubernates
- port lightship服务器端口
- gracefulShutdownTimeout 优雅停机前时间
- gracefulShutdownTimeout 优雅停机延迟时间
- shutdownHandlerTimeout 停机Handler前时间
- signals 标记
- terminate 用于shutdown停机的函数
访问端点:
- "/health": 健康状况,有如下几种返回:
- 200 status code, message "SERVER_IS_READY" 服务器就绪
- 500 status code, message "SERVER_IS_NOT_READY" 服务器正在初始化
- 500 status code, message "SERVER_IS_SHUTTING_DOWN" 服务器挂了
- "/live": 还活着吗,有如下几种返回:
- 200 status code, message "SERVER_IS_NOT_SHUTTING_DOWN".
- 500 status code, message "SERVER_IS_SHUTTING_DOWN".
- "/ready": 是否就绪,有如下几种返回:
- 200 status code, message "SERVER_IS_READY".
- 500 status code, message "SERVER_IS_NOT_READY".
Kubernates
Kubernates 提供了两个健康检查服务:liveness 和 readiness,你可以将 express 部署到 Kubernates 容器中。
后记
不蒙所盼,幸成此册,然曲终人散,当初的故人再也无缘相见